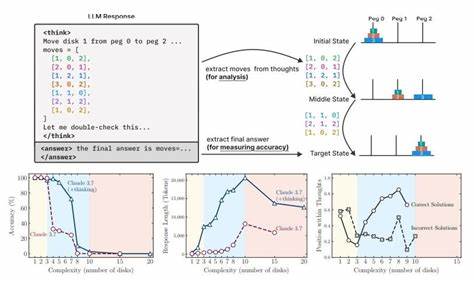
随着人工智能技术的迅速发展,通用人工智能(AGI)逐渐成为业界和学界关注的焦点。所谓通用人工智能,是指具备与人类相当甚至超越人类的全面思考及推理能力的智能系统。然而,苹果研究团队最近发表的研究报告指出,当前最先进的人工智能模型在推理能力方面依然存在显著不足,距离AGI的理想状态还有较大距离。苹果研究人员通过多维度测试,揭示了现有大型语言模型(LLMs)在面对复杂推理任务时表现出的固有限制,并指出传统评估体系忽略了对模型推理能力的深入探究。 主流AI语言模型如OpenAI的ChatGPT和Anthropic的Claude虽然在数学计算和代码生成等基准测试中表现优异,但苹果的研究表明,这些模型往往依赖于表面模式匹配与模仿推理路径,而非真正理解和内化推理的逻辑。研究团队设计了多种复杂谜题和推理游戏,从多层次考察模型推理过程,发现当任务复杂度提升时,模型的准确率显著下降,表现出推理能力的崩溃,且无法有效推广到新的推理情境。
这些核心发现挑战了普遍认知,认为大型语言模型通过规模扩展即可解决推理难题的假设。 跨越通用人工智能的门槛,不仅需要模型具备丰富的知识储备,还需具备严密缜密、可扩展的推理机制。苹果团队指出,目前的“思考型”大模型在进行复杂决策时出现了“过度思考”现象,即模型在早期阶段生成了正确答案,但随后的推理步骤却逐渐偏离正确轨道,导致错误答案的出现。这种不稳定且浅表的推理过程凸显大模型尚未真正掌握推理的底层算法,缺乏稳定且一致的演绎能力。 研究还揭示,现有评估方法过度关注最终答案的准确度,忽视了推理过程中的中间步骤及其合理性。苹果建议,在未来AI系统能力评测中,应加强对推理路径的审核和验证,以避免算法“走捷径”,仅仅通过训练数据统计规律获胜,而非真正“理解”问题本质。
此外,苹果研究批评当下一些乐观观点,认为距离AGI已经非常接近的言论过于理想化。虽然OpenAI和Anthropic的领导层表达了快速实现AGI的信心,但苹果的实证数据提醒业界,AI模型仍面临推理能力和通用化应用的根本挑战。现实情况是,仅凭模型容量增加或训练数据扩充难以自动解决推理复杂性和泛化能力不足的问题。 AGI的实现不仅是技术创新的跨越,更涉及对智能本质的深入理解。目前的AI模型,尤其是大型语言模型,依赖深度学习和海量数据训练,具备惊人的语言生成能力和轻度推理能力,但缺少人类思维中的系统性、连贯性和意图意识。苹果研究强调,未来AI研究需要结合逻辑推理、符号计算等多模态技术,构建更加稳健且透明的认知架构。
展望未来,随着AI技术的不断迭代,模型推理能力的提升仍是业界攻坚的重点方向。基于苹果团队的发现,如何设计能够在复杂任务中维持高准确率和推理稳定性的模型,将成为科研和工业界重点研究内容。同时,多方协作以完善AI评估体系、制定更加科学合理的推理能力测试标准,也将促进人工智能走向真正的通用智能时代。 总而言之,苹果研究的最新成果为人工智能领域敲响了警钟,现阶段AI模型距离真正的AGI标准仍有不小差距,尤其是在复杂推理与推理泛化能力上存在系统性瓶颈。尽管AI的发展充满希望,但理性认识技术现状与挑战,方能推动科学创新健康稳步前进。业界应重视推理过程的深度研究与模型本质机制的解析,努力克服现有技术短板,推动AI向真正智能化迈进。
未来通用人工智能的实现,需要的不只是技术突破,更是对智能本源的全面理解和跨学科的创新融合。