随着人工智能技术的不断进步,音频处理领域迎来了前所未有的发展机遇。尤其是在语音合成和编辑方面,传统模型虽然取得了显著成效,但在灵活编辑和高质量输出上仍然存在诸多限制。Play Diffusion作为一款开源的扩散模型,应运而生,为即时音频编辑带来了革命性的突破。它不仅优化了音频局部修改的流程,还极大提升了编辑后的连贯性与自然度,成为语音科技创新的又一里程碑。 传统的自回归变换器模型在语音生成领域取得了引人注目的成果。它们通过逐步预测下一个音频标记,能够生成连贯流畅的语音。
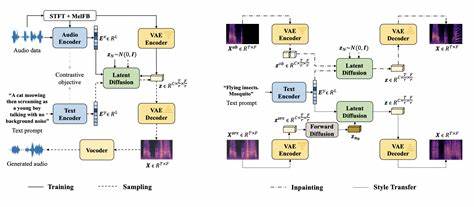
但这种逐步生成的机制带来了诸多挑战,特别是在音频局部修改时,必须重新生成整段音频或从中间某一点重新合成,这不仅计算资源消耗大,而且容易导致语调和节奏上的不一致,影响听感体验。更有甚者,直接替换某些词汇往往会产生明显的边界不连贯感,使得编辑结果无法媲美原声质量。 Play Diffusion基于扩散模型的新颖思路,彻底改变了这一局限。它首先将音频波形编码成一系列离散的音频令牌,形成一种紧凑且可操作的表达方式。针对需要修改的音频段,模型通过遮罩机制隐藏该部分令牌,然后在保留上下文音频信息的基础上,根据更新后的文本提示,利用扩散过程逐步去噪,恢复被遮罩区域的高质量音频令牌。这种非自回归的生成方式允许同时对所有令牌进行处理,避免了传统方法中一边生成一边依赖前序信息的低效,同时有效保证了编辑内容与上下文的自然融合。
Play Diffusion的核心优势在于其能够无缝维护说话人特征及语音韵律。这得益于其集成的大规模预训练语音编码器与解码器,其中BigVGAN解码器将生成的令牌序列转换回高保真音频波形,同时配合说话人嵌入向量,实现对声音身份和情绪的精确还原。这意味着无论是轻微修改词汇,还是大幅度调整语句内容,最终输出的声音都能保持稳定一致,犹如原声现场录制般自然。 此外,Play Diffusion的设计充分考虑了效率和实用性。在生成长时间语音时,传统自回归模型极度耗时,因为每个标记必须依次生成。相比之下,扩散模型允许一次性生成全部令牌,只需经过有限次数的迭代去噪步骤即可完成,显著降低了计算复杂度。
以50Hz采样率的音频为例,生成20秒语音在自回归框架可能需要多达1000步,而扩散模型只需不到20步,速度提升超过50倍,为实时音频编辑和在线应用奠定了基础。 模型训练阶段,Play Diffusion采用了创新的非因果掩码机制,区别于传统语言模型仅依赖历史信息,其允许模型同时关注音频序列的前后上下文,提升预测的准确性和鲁棒性。训练过程中,模型随机遮蔽部分音频令牌,以文本条件及说话人信息为依据,学习如何精确复原这些遮罩区域。此方法不仅增强了模型的通用性,还使其能灵活适应从部分音频片段修改到整段语音合成的各种任务需求。 作为一个开源项目,Play Diffusion不仅提供了完整的模型权重和源码,还通过友好的用户界面实现了便捷的使用体验。用户可以在Play Studio中的Speech Editor里轻松上传音频、输入文本修改内容,系统即可自动完成高质量音频的局部替换。
社区活跃的支持和不断优化也使其在应用场景中不断扩展,例如语音助手个性化调教、影视后期配音替换、语言学习辅助朗读乃至语音隐私保护等领域,展现出极大的市场潜力。 未来,随着更多多模态扩散模型的融合与提升,Play Diffusion有望支持跨语言、跨风格的语音转换和编辑,进一步丰富用户表达的自由度。其技术框架同样可以延伸到音乐制作、声音环境建模及虚拟现实互动语音等更广泛的声音合成应用中。凭借其高效、灵活且开放的特性,Play Diffusion正在引领音频编辑迈入智能自动化的新阶段,成为推动音频技术革新的重要引擎。 总的来说,Play Diffusion代表了音频编辑技术发展的前沿趋势。通过结合扩散模型的创新架构、多模态条件控制以及高保真解码方案,它完美解决了传统语音生成编辑中的难题,实现了真实、流畅且高效的语音修改体验。
无论是内容创作者、开发者还是普通用户,都可以借助这一强大工具轻松完成各类语音编辑任务。随着技术的不断成熟,Play Diffusion必将助力语音交互产品和数字媒体产业实现更大突破,推动数字声音进入更加智能化和个性化的新时代。