随着人工智能技术的飞速发展,深度学习模型的规模和复杂度不断攀升,这对计算资源提出了更高的要求。为了突破单个设备内存和计算能力的限制,研究者们发展出多种并行计算技术,张量并行(Tensor Parallelism)作为其中关键的一环,正在成为实现超大规模神经网络训练和推理的重要策略。理解张量并行的核心原理与实际应用,对于提升模型运行效率和扩展能力至关重要。 深度学习模型的并行计算主要包括数据并行、流水线并行以及张量并行三种模式。数据并行通过复制完整模型到多个设备,分割输入数据批次以实现高速率计算,适合批量大小较大且模型能适配单设备内存的场景。流水线并行则将模型的各层划分给不同设备,构建流水线加速执行,虽能解决单设备内存不足的瓶颈,但存在多设备利用不均衡与启动停机阶段效率低下的问题。
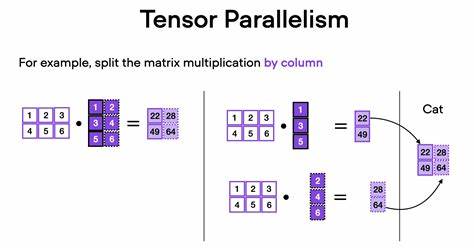
与此相比,张量并行细化到模型内部计算,将单层的计算任务沿张量维度拆分成多个子任务,分布到多个设备上协同处理,通过通信操作保证整体计算结果与单设备执行保持一致。 张量并行的精髓在于对矩阵运算的分块和分配。以矩阵乘法为核心的神经网络层为例,输入张量和权重矩阵可以被视作由多块子矩阵组合而成的块矩阵。基于块矩阵的特点,张量并行可将整个矩阵乘法拆分为多组子矩阵间的乘加计算,而这些子计算任务分布到多个设备上并行执行。张量并行的优化重点在于选择合理的分块策略与通信方案,从而降低设备间通信开销,提升整体执行效率。 常用的张量分块策略主要包括列向切分(column-wise sharding)、行向切分(row-wise sharding)以及成对切分(pairwise sharding)。
列向切分是将权重矩阵按列切分,各切分部分独立承担对应子计算,输入张量保持完整拷贝到各设备。此时,每个设备计算出部分输出张量,通过All-Gather通信操作将结果拼接还原完整结果。行向切分则对应通过切分输入张量并与行切分的权重矩阵相乘,每个设备输出的部分结果需借助All-Reduce通信进行求和合并。成对切分则巧妙组合两种切分方式,利用列向切分与行向切分的交替应用有效减少通信次数和冗余计算,从而在复杂层结构如变换器的前馈层和注意力层中表现优越。 进一步来看,在复杂神经网络的训练过程中,张量并行的梯度计算也需兼顾不同分块策略的反向传导同步。由于反向传播中权重矩阵需转置计算,张量并行的分块策略在反向传播时呈现"翻转"特性,即正向计算中行切分对应反向为列切分,反之亦然。
成对切分在前向反向均保持相同切分模式,有助于简化梯度同步。显然,张量分块策略的恰当选择不仅关乎计算效率,也直接影响梯度传播的正确性和通信负担。 实施张量并行的技术手段多样,当前主流分为单程序多数据(SPMD)范式、分布式张量(Distributed Tensors)和自动并行化工具。SPMD模式下,用户需深入分析模型结构,结合通信原语手动实现张量分块与数据同步,典型如Megatron-LM和PopXL GPT-3等项目。分布式张量接口则通过框架级别屏蔽复杂性,提供类似于本地张量的抽象,方便用户调用,同时保证底层并行运行。诸如PyTorch的DTensor和OneFlow的相应实现正积极推动这类技术的普及。
相比之下,自动并行化尝试借助分析和搜索技术自动选择最佳分块方案,如Alpa项目,虽然目前尚处于早期阶段,但长远来看具有巨大发展潜力。 在大型模型训练场景,张量并行的优势尤为突出。它不仅有效扩展了可训练模型的参数规模,也降低了单设备的存储压力,提升硬件资源利用率。然而,张量并行伴随较高的设备间通信需求,尤其是在大规模集群环境下,通信延迟和带宽瓶颈可能成为性能瓶颈。此外,模型的分块不合理可能导致计算负载不均或额外通信开销,影响整体效率,因而高效的分块规划和通信优化是核心研究热点。 综上所述,张量并行作为深度学习并行计算范式的重要组成部分,凭借其细粒度分块和灵活的计算拆分能力,助力业界破解超大规模模型训练的难题。
深入理解张量并行的分块策略、通信机制与梯度计算方法,不仅有助于优化现有模型的执行效率,也为未来更复杂神经网络结构的设计提供坚实基础。随着分布式框架和自动并行技术的持续进步,张量并行的应用门槛将不断降低,助力更多研发团队实现创新突破,引领人工智能技术迈向更高峰。 。