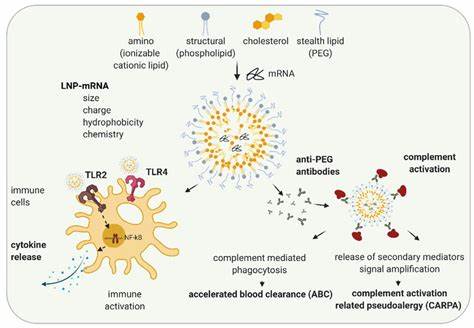
在当今人工智能和机器学习的快速发展中,模型性能的提升成为研究和应用的核心目标。传统的深度学习模型通过大量数据进行训练,虽然取得了显著成绩,但随着应用需求的复杂化,单纯依赖监督学习已难以满足高精度和鲁棒性的要求。强化微调作为一种结合强化学习和微调技术的创新手段,逐渐成为提升模型效果的重要策略。本文将深入探讨强化微调的基本原理、实现方法及其在实际应用中的优势和挑战,帮助读者全面掌握这一前沿技术。强化微调的核心思路是在已有的预训练模型基础上,引入强化学习的训练机制,通过与环境的交互优化模型行为,使模型尤其是在决策和生成类任务中的表现更为优异。传统微调通常基于监督数据集进行梯度更新,而强化微调则利用奖励信号指导模型学习,从而能够适应更加动态和复杂的任务需求。
例如,在自然语言生成中,模型通过接收关于生成文本质量的反馈,逐步调整策略,生成更加符合预期的内容。强化微调的优势主要体现在几个方面。首先,它能够更灵活地处理那些难以用固定标注数据覆盖的任务,通过环境交互获得实时反馈,实现模型行为的个性化和实时优化。其次,强化微调能够帮助模型更好地平衡探索和利用,例如在推荐系统或对话系统中,既保证新颖性也保证用户满意度。再次,这一方法可以减少对大量标注数据的依赖,通过智能的奖励设计,利用少量或无标注数据进行有效训练。实现强化微调的关键在于合理设计奖励机制和环境交互方式。
奖励函数的设计需要紧密契合任务目标,既要能够量化模型的性能提升,也要避免陷入局部最优。此外,环境的模拟需要尽可能逼真,确保模型在训练过程中得到有效反馈。例如在自动驾驶系统的强化微调中,虚拟仿真环境的真实性直接影响模型训练效果。策略优化算法也是强化微调中的重要环节,目前常用的包括策略梯度法、近端策略优化(PPO)以及演员-评论家方法等。这些算法能够稳定高效地更新模型参数,促进在复杂环境中的学习和适应。强化微调不仅在理论上具有吸引力,在实际应用中也展示出了广阔前景。
以自然语言处理为例, OpenAI 的 GPT 系系列模型通过强化微调技术显著提升了生成文本的自然度和任务相关性。在计算机视觉领域,强化微调被用于优化目标检测和场景理解算法,提高了模型在动态和复杂场景中的表现能力。与此同时,强化微调也面临一定挑战。首先,训练过程计算资源消耗较大,尤其是在需要大量环境交互的任务中,训练成本较高。其次,奖励机制设计难度大,稍有不慎就可能导致模型学习到不合理的策略。再者,强化微调过程中模型可能出现不稳定甚至退化,需要经验和调试确保训练效果。
此外,强化微调的推广还受到部分领域数据隐私和安全性考虑的制约。尽管如此,随着计算能力的提升和算法的优化,强化微调的应用门槛正在逐渐降低,越来越多的研究和工业实践开始尝试将其纳入模型训练流程。未来,强化微调有望与迁移学习、多任务学习等先进技术结合,形成更加智能和高效的训练体系,推动人工智能在医疗、自动驾驶、金融等多个关键领域的应用进步。总结来看,强化微调作为提升模型性能的有效手段,融合了强化学习的动态反馈机制和预训练模型的知识优势,为应对复杂任务提供了创新途径。通过科学设计训练环境与奖励机制,结合先进的策略优化算法,强化微调不仅提升了模型的表现力和适应性,也推动了人工智能技术的实用化进程。在未来,随着相关技术的不断成熟和发展,强化微调将在更多实际场景中展现出巨大潜力,帮助构建更加智能、可靠和高效的人工智能系统。
。