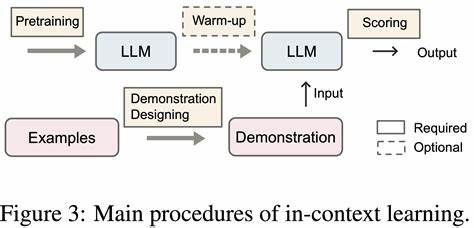
近年来,大型语言模型(LLM)在自然语言处理领域展现出卓越的性能,推动了机器翻译、文本生成、语义理解等多个技术应用的突破。然而,即使是最先进的模型,仍然面临着"幻觉"问题,即生成内容时出现对事实不准确甚至错误的陈述,这种现象严重影响了模型的可信度与实用价值。幻觉的成因复杂,既包括训练数据的不完整和偏颇,也有模型本身过拟合、欠拟合的情况,更源于缺乏真实世界的实际经验及对模糊问题的处理不足。当前提高模型真实性的主流思路多依赖外部知识库进行知识检索增强,虽能一定程度缓解假信息,但带来了系统复杂度的大幅提升,且检索匹配不准确时仍会诱发错误输出。面对这一挑战,谷歌研究团队提出了名为"自演化logits解码"(Self Logits Evolution Decoding,简称SLED)的创新方法,从模型内部机制角度突破,绕开对外部数据的依赖,通过充分利用模型所有层级的输出信息,极大提升生成文本的精准性和事实一致性。大型语言模型通常基于Transformer结构,文本处理分为多个中间层,每一层都会产生一系列"logits",即预测的分数,传统文本生成过程只选用最终一层输出的logits来决定下一个词或符号。
然而,模型各层的early exit logits包含了丰富的多角度观点和细微信息,可能捕捉到最终层未完全体现的上下文细节和逻辑推理。SLED的核心思想就是将所有层的logits转换为概率分布,并通过加权平均整合这些信息,将每层预测作为相互补充的证据源,从而重新定义下一步输出的可能性分布,让模型输出更贴近真实世界知识。举一个直观案例,当模型被问及"英属哥伦比亚的省会是什么城市",传统只利用最终层logits的方法往往容易选择大众知名度更高但不准确的"温哥华",而采用SLED后,结合所有层信息,最终赋予正确答案"维多利亚"更高概率,成功避免了表象的误导。另一个典型应用场景是在多步骤数学计算问题中,例如"艾什买了6个玩具,每个10令牌,四个及以上享受九折优惠,请问实际需要支付多少?"传统模型仅依赖最后一层的"6×10=60"计算公式,忽略了折扣信息;但SLED方法发现多个中间层倾向于预测继续乘以折扣系数"0.9",最终导出正确计算"6×10×0.9=54",有效纠正了基于常见训练数据模式的错误估计。谷歌研究团队将SLED应用于不同规模和结构的开放式语言模型,如GPT-OSS、Mistral及Gemma系列,分别在多项事实核查、多选题判断及自由生成文本等多元任务中取得显著提升。实验结果显示,相较于传统解码方法,SLED在保持稳定推理流程的同时,能够将准确率提高多达16%,同时仅带来约4%的推理时间增长,展现出极高的实用价值。
此外,SLED还能与其他先进的真实性解码策略如DoLa联合使用,协同作用下进一步抑制模型幻觉,彰显其灵活拓展性。SLED宏观上不仅是解码策略的革新,更是激活大型语言模型内部潜力的有效途径。通过挖掘模型深层次的多角度信号,实现了对多模态、多步推理及复杂上下文的更全面理解。未来,结合监督微调技术,有望将SLED应用拓展至视觉问答、代码生成、长文本写作等更多领域。毫无疑问,这种依托模型自身结构优化输出的思路,将成为提升AI语言智能可信度和实用性的关键路径。作为开源贡献,SLED代码已在GitHub平台发布,为全球开发者提供了可直接使用的工具包和示范,推动学术界与工业界共同探索与发展。
在日益增长的人工智能应用需求下,准确性和真实性成为用户体验的核心要素。SLED为当前行业带来了新的思路与标准,打破依赖外部检索的瓶颈,强化了模型对自身内部知识的理解与利用,期待这一创新解码策略能够助力更多自然语言处理场景迈向更高水平的可靠智能。综合来看,SLED不仅提升了大型语言模型的生成可信度,解决了长久困扰人工智能领域的幻觉难题,也为未来深度模型架构的优化和多任务融合开辟了新方向。大型语言模型正以更准确、更稳健的姿态融入我们的日常生活和专业工作中,开创智能交互与知识服务的新纪元。 。