在当今快节奏的数字世界中,实时数据处理和响应速度成为应用程序竞争力的重要因素。传统的单机服务往往难以承受突发流量或持续增长的请求压力,因此如何动态扩展反应式服务成为开发者亟需解决的问题。Skip作为一门专注于高效反应式计算的编程语言,其独特的计算图结构为构建实时服务提供了坚实基础。结合近年来日益成熟的容器编排技术Kubernetes,Skip服务的动态伸缩能力得到了极大提升,进一步满足了现代分布式系统对可靠性和灵活性的需求。 Skip语言的核心优势在于其高效的反应式计算图结构。该计算图能够准确地表达输入变化与输出之间的依赖关系,确保系统只在必要时执行最小量的重新计算,从而大幅节省计算资源和降低延迟。
通过将整个反应式系统以原生方式实现于Skip语言中,开发者能够轻松构造复杂的实时数据流响应逻辑,同时避免传统框架中常见的性能瓶颈。 然而,单机运行的Skip服务在面对高并发或流量激增时难以满足性能需求。为此,Skip提出了基于Leader/Follower架构的分布式扩展方案。该架构中,服务被拆分为共享的计算图以及按需生成的用户资源实例。Leader节点负责维护共享的计算部分,确保数据结构和中间计算结果在跨客户端间保持最新。Follower节点则专注于实例化用户特定的资源,处理各自分配的客户端请求。
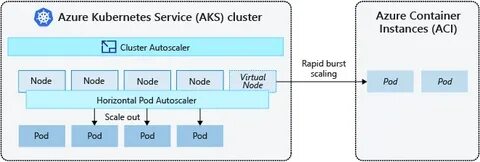
通过这种方式,系统可以在多台机器间分担资源实例的计算压力,同时保证共享计算图的一致性和实时性。 Leader节点对外维护单一权威的共享计算图,以稳定且高效的方式计算和同步服务基础数据。Follower节点则通过镜像该共享计算图,对各自分配的客户端请求进行个性化扩展,实现延迟极低的用户定制数据流。客户端的请求通过反向代理层分配至各Follower,有效平衡负载,并避免单点压力。该架构使得即使在高并发场景下,也能维持服务的低延迟和准确性,不仅保障了系统的可用性,更极大提升了并发处理能力。 为了进一步简化部署和扩展流程,Skip团队开发了完整的Kubernetes支持方案。
通过将Skip服务封装成Kubernetes StatefulSet,实现每个Pod的网络标识稳定且唯一,方便流量的有序调度。Kubernetes强大的自动化管理能力使得服务的水平扩展和收缩流程变得简洁直观,用户仅需执行简单的命令如kubectl scale即可动态调整资源副本数量。 Kubernetes内置的负载均衡和服务发现机制与Skip的Leader/Follower架构天然契合。新增Pod在启动时会自动注册至集群的入口负载均衡,随后接收流量并同步共享计算图。流量的路由依据数据流标识准确转发至对应Follower Pod,避免请求转发混乱。缩容时Pod被稳定地剔除出负载均衡池,确保无中断地平滑停机。
整个过程对客户端透明,无需应用层调整,极大提升了运维友好性和产品稳定性。 Skip与Kubernetes的结合为构建复杂且高效的分布式反应式服务指明了方向。无论是新闻推送、实时监控、金融交易流还是在线协作平台,这种架构均可帮助开发者应对业务的剧烈波动和不断增长的用户基数。Skip的响应式计算模型保证了数据的准确性和实时性,而Kubernetes保障了服务部署的灵活性和高可用性。 此外,Skip团队积极开放示例项目和丰富的配置文档,帮助开发者快速上手并根据自身需求定制扩展方案。通过项目脚手架工具和多种部署示例,用户可以轻松体验Skip在分布式和容器化环境中的表现,快速验证业务逻辑和性能预期。
在社区的持续推动下,Skip与Kubernetes的生态正在不断完善,未来将支持更多框架和技术栈的整合应用,助力开发者打造更智能、更高效的反应式服务。 总而言之,利用Skip语言的高效反应式计算能力和Kubernetes的弹性调度机制,企业和开发者能够构建适应动态流量需求的现代分布式后台系统。这种组合不仅提升了系统处理能力,降低了运维复杂度,更显著优化了用户体验。随着物联网、边缘计算和云原生技术的快速发展,跳转到动态扩展的反应式服务平台将成为数字化转型的重要基石。未来,Skip与Kubernetes的深度结合将不断推动实时数据服务的创新边界,赋能广大开发者构筑更坚韧、更智能的互联网应用生态。