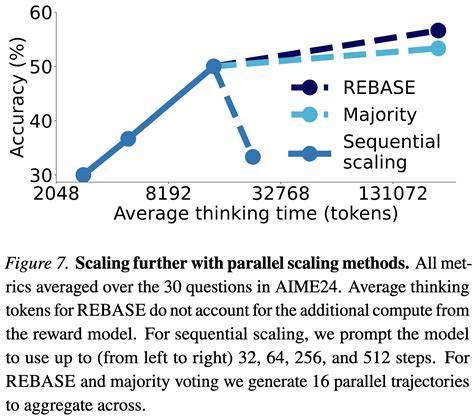
在当今数字化飞速发展的时代,平台的可靠性成为技术企业能否长期生存和赢得用户信任的关键。然而,随着用户规模不断扩大,许多曾经稳定的系统开始暴露出前所未有的挑战。一个典型的例子便是某技术平台在爆发式增长后所遭遇的一系列可靠性困境。尽管流量和用户数的激增象征着成功,但其背后的技术系统却在难以承受的压力下频繁出错,给用户带来不便,也给公司带来了巨大的生存压力。用户期待能够稳定地部署和运行自己的应用,然而平台的架构并未能完全跟上增长步伐,导致体验严重落差。 这一平台的架构由多个关键部分组成,包括中央认证及数据操作的API、利用WireGuard网关连接私有网络的flyctl工具、远程Docker构建虚拟机、全球Docker镜像注册中心、用于秘密管理的HashiCorp Vault、基于Nomad的调度器、负责服务发现的系统、流量代理以及支持应用间互联的网络基础设施。
这些系统必须协同工作,确保应用能够在部署后保持长期运行。然而,每一个环节都存在独特的缺陷和失败风险。 服务发现的难题尤其突出。最初平台采用HashiCorp Consul作为全局服务发现工具,但Consul设计初衷是适用于单个数据中心的集中式服务器架构,而非全球分布式环境。于是,因所有状态更新都需经过跨大陆的服务器群集,导致数据频繁陈旧,代理错误地将请求导向已过期的接口,私有DNS记录也经常延迟更新。为解决此痛点,平台团队开发了名为Corrosion的新型基于gossip协议的服务发现系统,旨在实现全球范围内秒级变更传播。
尽管Corrosion更适合分布式环境,但其新颖的架构带来了一些稳定性挑战,例如内部DDoS状况和数据库更新时意外问题,导致应用部署时代理和DNS使用陈旧数据,应用因此短暂中断。这一经历反映出新技术创新虽然必要,但也需经过严谨打磨提高容错和稳定能力。中间临时解决方案和未来更根本的架构调整都是提升服务发现可靠性的必由之路。 秘密管理方面,平台依赖同样采用集中式架构的HashiCorp Vault。每当新虚拟机启动,系统都必须从Vault中拉取应用所需的敏感信息。由于Vault服务器位于美国,而各区域间网络状况不稳定,远距离连接导致访问失败成为常见问题。
此外硬件故障曾引发覆盖范围广的虚拟机创建异常。这种集中式系统本质上的地域依赖和单点故障风险,再次暴露了其在全球多地部署场景中适应性不足的问题。改用Fly机器并减少重新创建频次在一定程度上缓解,但若Vault整体状态不佳,新机器也无法正常启动。这一情况印证了选用现成开源软件往往要在功能和全球可用性之间权衡。 数据库方面,平台的Postgres集群经历了两大难题。首先,早期版本采用基于Stolon的集群方案,后台依赖Consul维护连接,故而Consul的异常直接影响数据库稳定。
新的设计改用repmgr管理主节点选举,减少了对外部协调服务依赖,提高了集群独立性和韧性。然而传统存量数据库的升级过程复杂,面临一定难度。其次,平台曾推出“非管理型Postgres”以等待第三方托管服务,但这一策略引发了用户预期与实际体验不符的负面反馈。大多数竞争对手提供的是全管理型数据库解决方案,用户默认的“轻松启动Postgres”意味着背后有完善的托管支持。平台的非管理型方案承诺未兑现,成为用户升级难点和满意度下滑的来源。当前官方已明确将开发托管型Postgres置为核心战略,认识到改进数据库服务对整体基础设施不可或缺。
容量规划失误同样对可靠性构成威胁。多个地区服务器资源枯竭,尤其在法兰克福等热门区域,多次出现无法满足新用户上线需求的尴尬局面。计划不足与增长速度不匹配,使得热点区域压力骤增。此前团队预期可通过阻止特定区域新用户接入缓解问题,然而实际效用不佳。Heroku用户大规模迁移到平台的高潮阶段带来了流量和应用数几何级数的增长,约30%的月增长率远超早期约15%。负责人坦言未能及时投入应对,随着团队扩充和组织调整,容量管理逐步规范。
另一个值得关注的问题是存储卷绑定于指定硬件服务器,虽然设计时强调通过多副本防止单点故障,但因卷与主机物理绑定,主机下线时应用也被迫停机。内存和CPU资源不足亦可能导致无法部署新虚拟机。该机制虽设计初衷良好,却因未能有效表达限制条件,导致用户期望与实际体验差距大,进而引发不满。相较之下,传统云服务商诸如AWS Elastic Block Store(EBS)则具备自动迁移与弹性扩容能力,平台的实现存在一定的劣势。 透明且及时的状态通告也是提升信任的重要环节。平台因对各种事件的状态页信息更新不够详尽而受到用户批评。
故障发生时,缺乏快速、详细的公共沟通让用户感觉被忽视,造成口碑负面循环。平台意识到该问题严重,并计划通过扩充运维团队、完善事故响应标准和打造个性化状态页面,提升事件信息的发布效率和精准度。新状态页可实时反馈硬件故障影响的具体客户范围,助力用户了解自身受影响状况,减少猜测和焦虑。 这一系列问题清晰地反映出,技术平台在迅速成长过程中,原有架构和工具面临诸多限制。现成开源项目虽具备开箱即用优势,但往往针对单一数据中心设计,其全球化部署场景带来的性能和稳定性挑战不容忽视。团队面对种种技术和组织障碍,正在通过自研项目、系统升级以及人员扩张等多重手段逐步修补短板。
未来,平台的稳定性改善不仅需在技术层面持续革新,还要加强与用户的沟通和反馈机制,确保开发者能够获得透明的信息并理解故障成因及应对措施。托管型数据库的引入、服务发现系统的完善、容量弹性提升和存储方案的优化,都是构建可信赖平台的关键举措。任何一家希望在竞争激烈的云服务市场立足的企业,必须正视技术成长中的阵痛,基于用户需求持续迭代和优化。 总之,当一个技术平台走入高速扩张阶段,可靠性问题往往随之浮现。解决这些问题需要深刻理解底层系统的局限和用户的真实期待,同时以坚定的执行力和技术创新精神推进平台架构演进。只有这样,才能摆脱“频繁宕机”“不够稳定”的标签,实现真正的生产级可信赖,并最终赢得开发者的认可与忠诚。
。