近年来,随着人工智能技术的快速发展,语言模型成为推动自然语言处理领域革新的重要力量。大型语言模型在文本生成、问答和推理任务中展现出令人瞩目的能力,但仍面临提升推理准确性和应对复杂问题的挑战。针对这些问题,S1(Simple Test-Time Scaling,简单测试时扩展)作为一种创新方法被提出,利用额外的测试时计算资源来改善模型性能,尤其在数学推理等领域表现优异。本文将深入解读S1的核心思想、技术细节、实际效果及其对未来语言模型发展的启示。 S1方法的提出背景源于对现有语言模型推理能力的反思。虽然大型预训练模型具备强大的语言理解和生成能力,但在处理复杂逻辑推理时常常出现错误。
传统优化手段多集中于训练阶段,通过增加数据量或优化模型结构提升性能,但这类方法成本高昂且难以快速迭代。相比之下,S1采用测试时动态调控模型“思考”时间的策略,能够在保持模型结构不变的前提下,通过增加推理步骤数或延长生成过程,提高答案的准确性。这样,“用时多一点,思考更深”成为提升推理表现的关键。 具体来说,S1引入了名为“预算强制”(budget forcing)的技术,旨在控制模型的测试时计算预算。模型在生成过程中通常会自动判断何时结束输出答案,而预算强制则通过强制模型多次生成“等待”(Wait)指令,延长其推理思维步骤,避免过早收尾。同时,如果模型试图提前结束回答,预算强制会直接终止生成过程,迫使模型多次检查和修正自身推理链条。
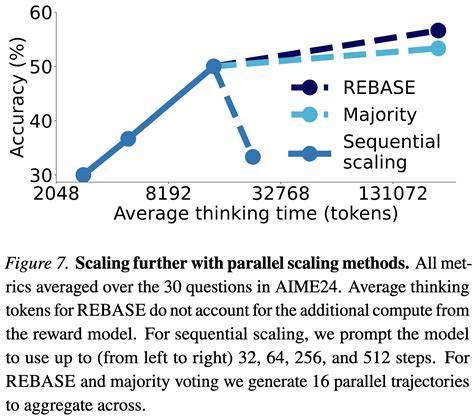
该方式有效减少了因跳步或遗漏而导致的错误推理,提升了模型推理的严谨性和可信度。 为了训练并验证这一方法,研究团队精心策划了s1K数据集。该数据集包含1000个精选的复杂问题,每个问题都配有详尽的推理路径,确保训练数据的难度、丰富性和质量均达到高标准。通过这一数据集对Qwen2.5-32B-Instruct模型进行监督微调,结合预算强制策略,S1方法在数学竞赛题目,如MATH和AIME24测试上的表现实现了显著提升,超过了先前的o1-preview模型,准确率提升高达27%。这证明了简单且有效的测试时扩展能够弥补训练阶段难以覆盖的推理挑战。 S1技术的成功不仅体现在模型的性能提升上,更在于其普适性和开放性。
该方法无需改变原有模型架构和训练流程,直接利用测试时的计算资源动态调整推理时长,使其易于应用于多种大规模语言模型。此外,S1的代码、数据和模型均开源发布,促进了社区的实践与二次创新,推动了测试时扩展策略在自然语言处理领域的深入发展。 从更广阔的视角来看,S1反映出人工智能算法设计中一个重要趋势:在模型训练成本和推理表现之间寻找更优平衡。传统依赖训练高昂计算资源提升模型能力的方法逐渐受到挑战,而测试时动态扩展计算预算则提供了一个灵活、低成本且效果显著的补充途径。通过延长推理步骤,模型有更多机会探索逻辑细节,纠正错误判断,从而实现推理质量的提升。 此外,S1方法对复杂任务和高阶推理需求的适配性表明,未来语言模型可以借助此类技术应对更具挑战性的应用场景,如学术研究辅助、程序推理甚至科学发现等领域。
通过合理配置测试时资源和扩展策略,语言模型或将突破当前能力瓶颈,达到比训练阶段表现更优秀的状态。 总结来看,S1:简单测试时扩展方法通过巧妙利用测试时计算预算,显著提升了大型语言模型在复杂推理任务中的表现,促进了AI推理能力的实质进步。其创新点在于通过预算强制机制延长模型“思考”时间,实现错误检测与修正,为应对计算资源限制与推理准确性争论提供了可行方案。随着模型规模的不断扩大以及测试时计算能力的增强,S1及其衍生产物有望成为推动语言模型智能化迈向新阶段的重要工具,开启更加智能、高效、可靠的人工智能应用时代。