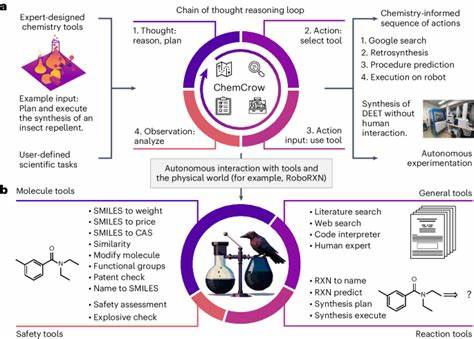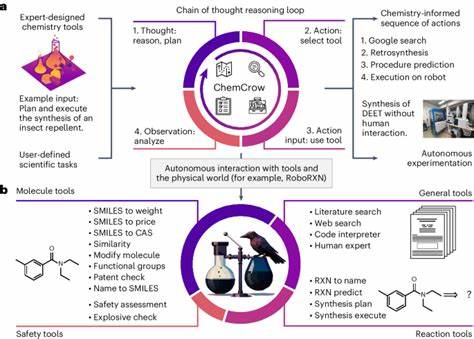
在人工智能快速进步的浪潮中,大型语言模型(LLMs)由于其强大的语言理解与生成能力,正在深刻影响包括化学在内的多个学科领域。作为通过海量文本数据训练而成的机器学习模型,它们不仅能够解读和生成自然语言,更开始承担起专业知识问答、数据挖掘乃至科研辅助的角色。特别是在化学科学中,这些模型展示了人类难以匹敌的知识广度与合理推理潜能,引发了科学界对其与专业化学家能力的广泛关注与深入讨论。 大型语言模型的化学实力来源于其对大量化学文献、教材及数据库文本的学习与内化。相比于传统化学家依赖的个人经验与专业训练,LLMs能够即时“阅读”并汇聚全球范围内的最新科学成果和知识储备,使其在信息量和检索速度上具备显著优势。最新的ChemBench框架评估显示,部分先进的LLMs在涵盖本科及研究生化学课程主题的2700多个题目上,整体表现甚至超过了参与测试的专业化学家。
这一事实不仅证明了其在化学知识层面的超凡记忆力,也体现了一定程度的跨领域推理能力。 尽管如此,现阶段大型语言模型仍难以完全替代化学专家。一个突出的问题是它们在处理基础但高度具体的化学任务时表现不佳,特别是涉及分子结构解析、核磁共振信号预测等需要深层空间推理和物理化学背景知识的复杂问题时,模型的准确率大幅下降。这表明当前模型倾向于基于训练数据中的模式记忆和表面关联作答,而非真正理解结构本质或进行化学直觉推理。与之相比,经验丰富的化学家虽然因人力阅读限制难以覆盖如此庞大的知识库,但在针对新颖复杂问题时,通常展现出更强的灵活思考与判断能力。 此外,模型在安全与毒理学等关键领域的表现也相对薄弱。
化学安全知识不仅要求准确无误的事实陈述,更涉及对潜在风险的严谨评估,这对于AI系统的透明度和可靠性提出了更高要求。评测中发现,部分LLMs对化学安全问题的回答过于自信,但误判率较高,且难以提供合理的不确定性估计。这种“过度自信”现象若未被妥善处理,可能对非专业用户带来错误引导,甚至引发安全隐患,凸显出提升模型校准能力的必要性。 为了更全面理解LLMs与化学专家之间的差距,ChemBench不仅涵盖多样化的主题,还针对知识、推理、计算与直觉等多重技能维度进行了细分。评测结果显示,不同模型在多领域知识掌握上表现参差,但规模更大、训练更广泛的模型普遍具备更强的综合能力。尤其值得注意的是,某些开源模型凭借优化升级已接近甚至媲美顶尖商业模型,这意味着公众和科研团体可以通过开源力量推动化学AI的发展,降低壁垒,激发创新。
该框架还特别考察了模型在“化学偏好”判定上的能力。这类任务要求模型模仿化学家的“直觉”,在相似分子间作出优化选择。在这方面,LLMs未能与资深化学家的判断形成显著一致,成绩接近随机猜测,反映出当前AI尚未掌握人类经验背后的潜隐模式或价值权衡。这为未来研究指明了方向:通过人类偏好调优或结合实验数据迭代训练,或可提升模型在复杂决策情境中的表现。 对于如何进一步提升大型语言模型的化学能力,专家们提出了多条路径。首先,丰富训练数据来源,尤其是将专业数据库如PubChem、Gestis等纳入训练语料,将有助于增强模型对专业细节的掌握。
其次,结合工具化系统(例如检索引擎、计算软件、实验控制平台)以实现工具增强的辅助推理,可以弥补纯文本模型的局限,提升回答的准确性与可靠度。最后,提升模型的自我评估和不确定性表达能力,对于确保系统使用安全和可信至关重要。 从教育角度来看,LLMs的成功挑战了传统化学教学和考试模式。与以往侧重记忆和熟练计算的教学不同,未来化学教育或需更强调批判性思维与创新性推理能力的培养,帮助学生与AI工具形成有效互动与协同,发挥各自优势。此外,出现能够辅助甚至超越人类专家的学习系统,也为科研方法论带来了革新可能,推动自主实验设计、数据分析和假设生成进入全新阶段。 总的来说,大型语言模型在化学知识掌握和某些推理任务上展示了超越普通化学专家的能力,彰显出人工智能在专业科学领域的巨大潜力。
然而,当前阶段其在深层结构理解、化学直觉以及安全评估等关键方面仍有较大改进空间。只有不断完善训练资源、方法与评估体系,并结合专家智慧,未来AI才能成为真正意义上的化学“合作者”,为科学发现与教育开辟更加广阔的前景。ChemBench作为一个公开、系统且多维度的评估框架,不仅帮助揭示了大型语言模型的实际水平和瓶颈,同时也为推动化学智能化发展和安全应用奠定了坚实基础。随着技术的进步,人机协同必将成为化学研究和教学的新常态,带来前所未有的创新动力和效率提升。