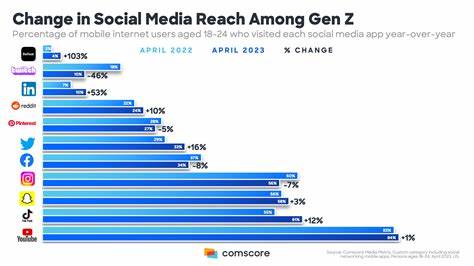
在数字时代,软件已经成为科研成果和技术创新的重要组成部分。随着开源项目和学术软件的广泛应用,如何对软件进行准确识别和溯源,成为学术界和产业界需要面对的重要问题。传统的数字对象标识符(DOI)虽然在文献和数据集的管理中发挥重要作用,但面对软件独特的结构和变化,往往力不从心。因此,软件哈希标识符(Software Hash Identifier,简称SWHID)应运而生,带来了软件身份识别的革命性变化。 SWHID是一种基于软件内容的内在标识符,其核心理念是通过计算软件代码本身的哈希值,为软件的各个组成部分生成唯一且不可变的“指纹”。这种方法类似于生物学中DNA序列的独特性,确保每一个代码片段、文件甚至整个版本都能被精准标识,避免了因依赖外部元数据或项目名称导致的混淆和误判。
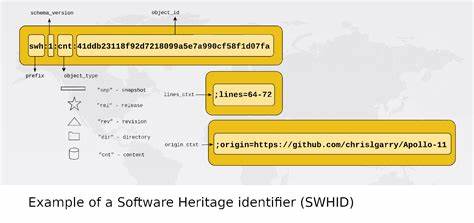
与外部标识符不同,SWHID直接绑定于软件内容,反映代码的真实状态和结构。通过这一特点,SWHID不仅具备强大的验证功能,还能支持软件引用、版本管理和再现性研究,有效提升科研和软件工程的透明度及可信度。 SWHID覆盖了多层级的软件结构,从单个代码文件的内容哈希,到目录及其内部文件的整体哈希,再到代码提交(commit)、发布版本(release)和时点快照(snapshot)等关键节点。具体而言,CNT表示文件内容,DIR代表目录级别,REV则对应代码提交,REL指明标记发布版本,而SNP则是捕捉某一时刻软件整体状态的快照。这些层级分明,满足不同应用场景对于细粒度识别的需求。 生成为自己的软件生成SWHID极为便捷,无需注册软件遗产库账户或具备代码所有权。
任何用户均可通过提供的命令行工具,在本地计算机上快速生成软件相关的哈希标识。只要遵循相同的计算模式,生成的SWHID与遗产库中对该软件版本生成的标识一致,实现了一致性和权威性的保障。此外,对于已经存档的软件制品,用户可直接在软件遗产平台页面获取其专属的SWHID永久链接。 SWHID结构清晰,由固定前缀SWH开头,紧跟模式版本、对象类型和哈希值等组件组成。上下文参数可选,用于表明软件来源地址、访问快照信息、参考锚点、文件路径及代码行范围等。这些附加信息有助于区分在不同仓库或目录结构中相同内容的代码变体,增强识别的精准性。
使用SWHID不仅能提升代码引用的准确度,还具备多种重要功能。首先,在学术出版物或技术报告中引入SWHID,能够让读者直接定位具体代码版本,保证引用的独立性和权威性。其次,基于内容的哈希机制,有助于实现软件版本的重复性验证,确保研究结果可被第三方科学重现。再次,SWHID可配合元数据文件如code meta.json或citation.cff等,自动生成符合学术规范的软件引用格式,简化学术稿件编写过程。 然而,SWHID并非适用于所有数字资源。其专注于软件代码内容,因而不推荐用于标识数据集或非软件文件。
对于日益崛起的AI生成代码,当前SWHID同样无法区分其生成来源,未来仍有改进空间。此外用户应避免将SWHID直接写入源代码文件中,否则内容改变将导致哈希更新,破坏内容一致性。促使用户采用独立的元数据文件管理标识符,是最佳实践。 未来,随着开源生态和研究软件持续高速发展,软件识别的需求必将日益增长。SWHID作为一种免费、可靠且易用的技术工具,将在软件保存、引用与溯源过程中发挥核心作用。其开放源码和社区支持背景保证了可持续演进,为科研社区和软件开发者带来更广泛的价值。
了解并掌握SWHID,不仅是提升软件管理效率的必要技能,更是推动科研诚信与数字可持续发展的重要环节。更多信息和工具可访问软件遗产官方网站及相关文档,通过自学和实践,任何科研机构、图书馆或开发团队都能充分利用SWHID实现软件资产的长期保存与精准识别,迎接数字时代软件知识产权与创新保护的新时代。