近年来,人工智能领域的飞速发展引发了学术界和公众对于未来AI突破时间节点的广泛关注。AI2027项目作为其中一个备受瞩目的AI时间预测模型,其提出的2027年超级智能代码编写者即将诞生的预言一度引发社会热议。然而,深入分析发现,这一模型的时间线预测存在明显的理论缺陷和实证证据不足,引发了不少专业人士的质疑和批评。本文将围绕AI2027团队所采用的时间线预测方法,详尽解析其模型结构、关键假设、参数设定的合理性及其与现实数据的吻合度,为关注AI进展的读者提供全面、客观的评估和思考。 AI2027模型试图通过“时间视域延伸模型”和“基准与差距模型”两种方法,预测AI成为超级代码编写者的时间点。所谓“超级代码编写者”被定义为能够以人类AI研究人员30倍速度和成本完成相同工作的AI。
据报道,该项目遵循了包括对人类与AI在指定任务时长上的比较,通过“时间视域”指标衡量AI能力提升的路径。然而,模型中的多个核心参数如初始时间视域、倍增周期和算法加速因子均是基于有限数据或带有主观判断的估计,缺乏充分的不确定性建模和充分的数据验证,导致预测结果的不稳定与偏差较大。 时间视域延伸模型重点依赖METR报告中AI在不同研发任务上的时间视域表现,原理上预测任务完成时间随时间指数级缩短。其中,倍增时间(即视域翻倍所需时间)被视为关键参数。然而,AI2027团队在设置初始时间视域时未充分反映历史数据中的不确定性,简单设定为固定值,同时忽视了近年可能由于任务发布延迟减少而产生的表面速度提升带来的误导。更为关键的是,其所采用的“超指数”增长曲线设计缺乏明确定义与现实依据,该曲线假定每次倍增所需时间都会以恒定比例减小,最终导致模型输出在近年达到数学上的奇异点甚至产生非实数,不符合现实物理意义。
模型作者给出的支持超指数增长的理由也不尽充分。有代表性的论据诸如“内外部模型发布时间差缩小”核心实际上可能产生相反效果,即进展速度被过度估计。另有所谓“任务难度差距递减”假设,声称任务难度随完成时长翻倍增加会降低,但未能提供实质数据佐证,更未结合当前大规模训练数据对AI表现影响的细致分析。此外,对近期局部加速的解释多建立在少量样本和不确定因素上,未能说明为何该加速必然持续,难以支撑模型中超指数整体趋势的设定。 针对模型中的“中间速度提升”环节,批评指出其算法和参数设定未能与AI研发实际进展节奏相匹配。该部分通过复杂的速度函数调整AI开发速率,试图模拟AI自身研发能力提升带来的加速反馈,但模型反向推测早期速度时,结果与开发者自身对2022至2024年研发加速幅度的估计大相径庭,表明模型未能准确归纳研发效率的历史演变,有悖于自主提升加速度的逻辑预期。
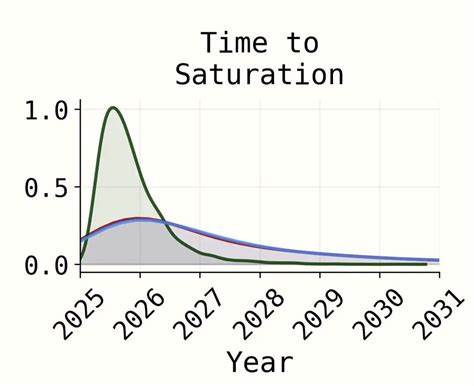
在“基准与差距模型”方面,模型试图以RE-Bench基准任务的表现为标尺,预测AI能力达到人类顶尖水平的时间,并设定随后完成更复杂任务所需填补的“差距”。然而,模型中RE-Bench表现饱和时间的假设及其与时间视域模型的参数连接存在明显不匹配,RE-Bench曲线拟合工作多基于人为设定的性能上限,缺乏坚实的实证基础。此外,模型核心参数多为非经验性猜测,流程中诸如饱和时间、增长率和研发速度等关键数据并未直接纳入代码和模拟,仅以主观调整代替,削弱了模型整体的科学严谨性。 从模型复杂度角度审视,AI2027的时间预测包含众多交织参数,这虽然提升了模型灵活性,但也引入过拟合和调参空间过大风险。随着参数数量增多,模型的预测不确定性本应显著提高,然而官方结果却呈现较为集中的时间预测区间。基于极度有限的历史数据点和有限的研发任务类型代表性,建构如此复杂模型恐怕难以抵御噪声和偏差干扰。
专家也指出,类似METR报告中诸多数据点数量稀少,无法支撑对超指数增长或复杂非线性趋势的可靠推断,采用简洁的指数模型反而更具稳健性和可解释性。 AI2027团队在疫情期间及发布后引发公众对近未来AI爆发性进步的广泛想象,然而其用于宣传的部分图表和曲线,尤其是公开流传的所谓“预测”曲线,与模型实际的中位数轨迹存在差异,且该图表设计基于简化假设或刻意调整。业界批评指出,这种缺乏清晰标注与真实性校正的传播方式,容易导致非专业受众误解其科学性和精准度,进而影响公众对AI发展速度和风险的合理认知。 最新的模型更新虽然修正了一些早期发现的缺陷,如增加了超指数衰减参数的不确定性建模,延迟了中位数预测时间至2030年左右,但核心问题仍未得到根本解决。研究者指出,新增的复杂模型引入了更多未公开说明的参数和假设,增加了模型的“黑箱”性质,同时未展示更充分的拟合历史数据的证据,尤其缺乏对重要假设的理论和实证验证。模型的“超指数延迟启动”逻辑更是倍受质疑,无法与合理的技术进展路径相匹配。
面对上述缺陷及模型预测结果的高度不确定性,有专家呼吁社会与政策制定者应谨慎对待AI时间预测,避免因过度依赖单一模型而导致决策失误。AI发展路径复杂多变,受到技术突破、数据资源、监管环境、经济投入与人才分布等多重因素影响,单纯依赖过去有限数据的趋势外推存在明显风险。更为合理的态度应是在承认不确定性的同时,发展多样化的预判模型,规划防范和应对不同速率AI进步的多套方案。 总结来看,AI2027模型通过详尽的数据收集和数学建模尝试对AI超智能代码编写者的诞生时间进行预测,但其多处关键假设缺乏充足证据支持,参数选择伴随高度主观判断与简化,多项复杂机制设计未能严格与实际研发进展和历史数据相吻合。模型的超指数增长设定在数学层面存在奇异点风险,且公开传播内容与实际模型输出存在偏差,致使其作为严谨科学预测的可信度备受质疑。在追求更准确AI发展时间预测的道路上,未来研究应注重模型的理论基础扎实性、充分的数据验证、多模型比较及更透明的参数不确定性呈现,以提升公众与决策者对AI变革时间的合理预期和适应准备。
。