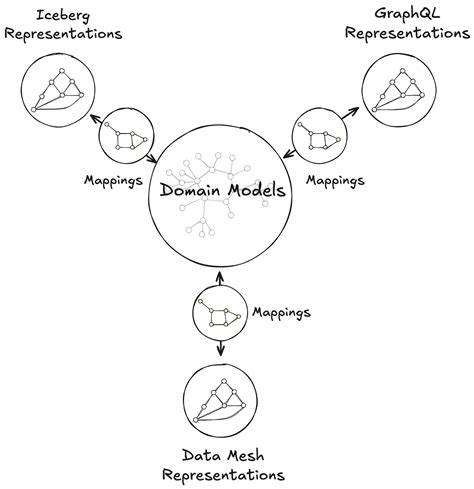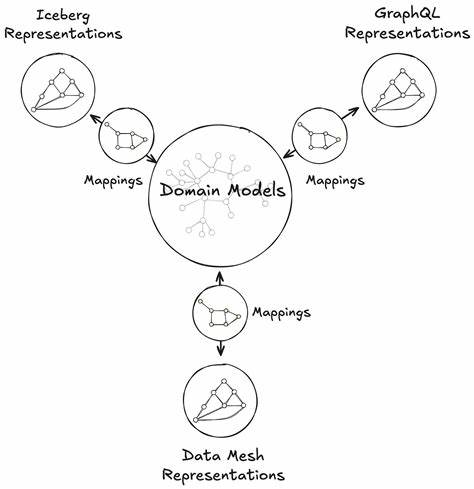
在当今数据驱动的时代,互联网企业对于大规模数据处理与分析的需求日益增长。Netflix作为全球领先的流媒体平台,凭借其强大的数据能力,打造了独特的统一数据架构(Unified Data Architecture,UDA),推动了企业数据处理的创新发展。本文聚焦于Netflix的UDA体系,特别是其核心理念——Model Once,Represent Everywhere,深入剖析这一策略如何帮助企业实现数据价值最大化,促进业务和技术的紧密融合。Netflix的数据生态设计面对海量、多样化的数据源,同时保障数据的准确性和可用性,在此背景下,UDA体系应运而生。该架构旨在消除企业内部不同数据系统和结构的隔阂,打造统一且易于扩展的数据管理平台。Model Once,Represent Everywhere的理念强调,这种架构允许开发者在数据模型构建阶段专注于精准表达业务语义,同时确保这些模型能够无缝应用于多个数据表示和消费场景。
换言之,设计一次数据模型即可在不同分析工具、服务和应用中重复利用,极大提升了开发效率和数据一致性。具体来看,Model Once的核心在于构建标准化且表达力强的数据模型。Netflix采用先进的数据建模技术,结合领域驱动设计(DDD)理念,确保模型紧贴业务实际需求,能够涵盖复杂的业务逻辑和多变的运营场景。与此同时,Representation Everywhere体现为充分利用统一数据模型驱动多个数据表示层面,包括报表、仪表盘、实时流处理以及机器学习模型的训练数据集等。通过这种设计,企业能够减轻数据重复加工和分散管理的负担,同时保证了不同数据消费端的一致性和准确性。统一数据架构还强调数据治理和数据质量保障。
例如,Netflix推行全链路数据溯源机制,确保每一数据变更都有清晰的记录和审核流程。数据安全与合规也是该架构的重要组成部分,利用加密、访问控制等技术手段保护数据隐私,满足相关法规的要求。Netflix UDA带来的价值显而易见。首先,它大幅提升了数据处理的效率,减少了数据工程师和分析师的重复劳动,让团队能够专注于更高层次的业务洞察和创新。此外,数据的一致性和准确性得到了保证,为智能推荐、用户画像、内容创作等关键业务提供了坚实基础。其次,统一架构赋能了多样化的应用场景。
无论是离线批处理还是实时分析,都能在同一模型之上高效运行,增强了系统的灵活性和适应能力。在技术选型方面,Netflix的UDA整合了多种开源与自研工具,如Apache Kafka用于流数据传输,Apache Flink或Spark用于流批一体化计算,数据仓库则依托于灵活可扩展的云计算基础设施。这些技术栈紧密结合统一的数据模型,实现了端到端的数据流水线自动化和智能化。除了技术层面的创新,Netflix在团队协作与文化建设方面也做出诸多努力。推动Model Once,Represent Everywhere战略落地,需要跨部门密切合作,确保数据策略与业务目标高度一致。Netflix倡导开放共享的数据文化,鼓励开发者积极参与模型设计和优化,促进知识沉淀与传承。
这种融合了技术与文化的综合实践,是UDA成功的关键所在。未来,随着数据量持续爆炸式增长和业务复杂度提升,Netflix的统一数据架构将不断进化。人工智能和机器学习技术的深入应用、边缘计算的兴起以及数据隐私法规的变化都将对UDA提出新的挑战和机遇。Netflix正不断探索创新方案,以保持其数据平台的领先地位和竞争优势。总结来看,Netflix的Model Once,Represent Everywhere理念为企业数据架构建设提供了宝贵的借鉴。通过构建标准化且复用性强的数据模型,实现数据表示的多样化应用,联合先进的数据治理和安全措施,Netflix打造了一套高效、可靠且灵活的统一数据架构体系。
该架构不仅提升了数据使用效率,还促进了企业智能化转型,助力其在激烈的市场竞争中持续保持领先。随着企业数字化深化,统一数据架构理念将愈发重要,各行各业均可根据自身特点借鉴Netflix的实践经验,推动数据资产的深度开发与创新应用,释放更多潜在价值。