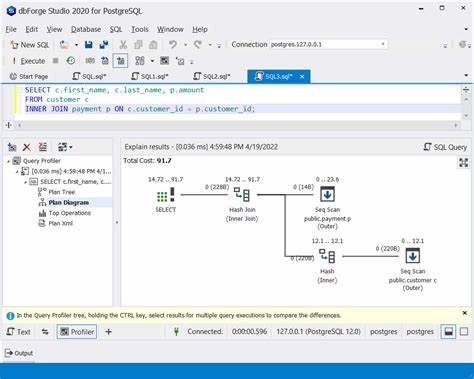
随着数据量的激增和业务复杂度的提升,PostgreSQL作为一款强大的开源关系型数据库,承担着越来越关键的角色。性能优化成为保障系统高效运行的核心环节,但如何科学地识别性能瓶颈并避免无谓的过度优化,是每位数据库管理员和开发者面临的难题。通过深入理解执行计划(EXPLAIN计划)的输出,结合合理的优化策略,可以在提升查询性能的同时确保系统维护的简洁和稳定。 性能瓶颈的定位始于对查询执行计划的详细分析。EXPLAIN ANALYZE命令不仅提供预估成本,也展示了实际执行时间和节点信息,帮助识别资源消耗最大的操作。例如,嵌套循环导致的多次扫描或大表的顺序扫描往往是性能瓶颈的罪魁祸首。
通过观察具体节点的执行时间比重,可以直观判断系统的阻塞点,如一个查询中一个表的并行顺序扫描耗时占总执行时间的80%,就应优先从该部分入手优化。除了执行时间,还需关注扫描方式,未被触发的索引扫描可能存在统计信息不准确或索引未命中的情况,进一步分析VACUUM和ANALYZE操作是否及时执行是关键。 针对发现的瓶颈,建立合适的索引是提升性能的有效手段。根据查询条件,尤其是WHERE子句中被频繁筛选的列,可以创建单列索引、组合索引或者部分索引。组合索引用于多条件过滤的场景能显著减少扫描范围,而部分索引则在满足特定条件时提升索引利用率,降低存储和维护成本。同时,需要评估列的基数,高基数列适合B树索引,低基数或者时间序列数据则可能更适合BRIN索引或者表分区策略。
值得注意的是,盲目添加新的索引会增加写操作的开销和存储压力,因此必须结合业务访问模式和数据分布进行理性设计。 数据库的日常维护操作对优化效果同样重要。VACUUM和ANALYZE命令通过清理死元组和更新统计信息,支持查询优化器做出更合理的执行计划选择。对于大型或活跃表,定期自动化执行这些操作可避免性能退化。此外,理解统计信息的准确性对索引使用决策影响巨大。若发现执行计划中索引扫描未被启用,应检查统计信息的及时性和准确性,必要时手动触发统计信息更新,确保优化器的决策基于真实数据。
避免过度优化是维护系统简洁性的关键理念。面对已经极快的查询响应时间,例如子毫秒级别的执行效率,过度细粒度地调整可能带来边际效应递减,反而增加系统负担。此时,重点应转向监控整体性能趋势,关注数据增长和查询模式的变化,而非频繁施加修改。通过合理的性能监控手段,实时捕捉潜在的性能波动,做到早发现、早修正。避免不必要索引的增加和复杂查询结构的堆叠,不仅减少维护难度,也降低引入新问题的风险。 借助执行计划准确定位瓶颈,与合理创建索引并结合日常维护策略,可以在大幅提升PostgreSQL查询性能的同时保持数据库环境的稳定和可管理。
数据工程和管理人员应把EXPLAIN ANALYZE作为排查的第一步,依据执行时间、扫描方式及索引利用情况制定科学的优化方案。同步注重监控和维护,避免短视的过度优化带来的反效果,建立基于数据驱动的持续优化机制。 总的来看,PostgreSQL性能优化是一门结合数据分析、系统维护和业务理解的综合艺术。通过有效识别性能瓶颈,建设性地优化查询路径,并谨慎权衡优化代价,能够确保数据库在应对日益增长的数据规模时依然保持高效响应。未来,随着数据和业务需求的不断演进,灵活运用上述方法,将为数据库系统的持续健康发展奠定坚实基础。