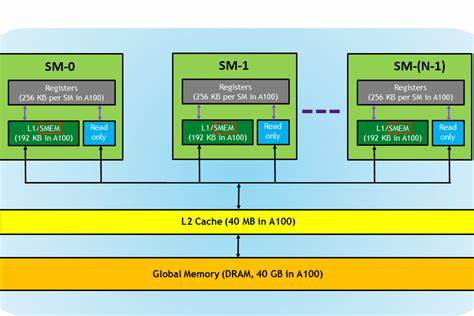
随着人工智能技术的迅猛发展,计算需求日益增长,图形处理单元(GPU)成为深度学习训练和推理的主力军。尤其是采用CUDA架构编写的人工智能内核,已成为提升算法执行效率的关键。然而,在当下GPU计算中,虽然Tensor Core的算力极为强大,内存带宽与延迟却逐渐成为制约性能提升的瓶颈。正因如此,内存优化被认为是开发高性能CUDA内核不可或缺的核心环节。 现代GPU架构中,Tensor Core以极高的速率执行矩阵运算,满足深度学习模型的算力需求,但前提是这些计算单元能够持续不断地获得数据,否则算力优势无法得以体现。此时,内存访问效率成为关键,如何高效地从全局内存、共享内存、寄存器等层级缓存中加载数据,确保计算核心不会因内存等待而空闲,成为了衡量内核优劣的重要指标。
影响CUDA内核性能的内存因素主要包括带宽利用率和延迟管理。全局内存容量大但访问延迟高,访问不当会严重拖慢程序速度。合理利用共享内存能够显著缩短数据访问时间,提高数据重用率。寄存器访问速度最快,但数量有限,如何科学分配寄存器以避免溢出则需要深谋远虑。通过优化线程协作访问路径,减少内存访问冲突,往往能取得显著提升。 在深度学习应用中,数据传输的方式尤为关键。
批量处理、多维数据布局、内存对齐、访存合并等技巧,均可有效减少内存事务数量与延迟。同时,合理调节线程块和网格结构,优化线程访问模式,实现合规化的内存访问,降低内存分支和非整合访存带来的性能损失。 对于CUDA内核的内存优化,最重要的是对内存层次结构的充分理解。全局内存访问成本最高,共享内存是速度和容量的折衷点,寄存器最快但数量有限。编程时应尽力将频繁访问的数据放入共享内存或寄存器,减少对全局内存的访问。共享内存的合理布置和同步机制保证线程间数据的协调,避免竞态和访问冲突。
使用原子操作(atomic)在某些深度学习应用中也能发挥作用,例如在权重更新、统计计数或异步累加时保证数据一致性,但过度依赖原子操作可能引发性能瓶颈,因为其会导致线程序列化,阻碍并行性。了解其适用场景和代价是编写高效内核的一项重要技能。 另外,利用CUDA内置的各种内存访问函数与指令能够降低手动优化的难度。例如使用__ldg函数实现只读缓存访问,减少一致性开销;利用warp shuffle指令实现warp内数据交换,突破共享内存带宽瓶颈,均是业内实践中的利器。 对于深度学习中矩阵乘法、卷积等核心算子,最佳实践是实现数据预加载,将全局内存数据批量搬运到共享内存,由线程协同完成复杂计算操作,既保证数据局部性,又充分发挥计算单元的吞吐量。同时,使用流多个CUDA流完成异步数据传输与计算的重叠,也能提升内存传输效率,减少整体等待时间。
巧妙设计内存访问模式还需要关注数据的存储格式。对于卷积运算,数据以NCHW或NHWC格式存储对内存访问效率有显著影响。根据目标硬件的访问规律和缓存策略,调整数据布局可避免越界访问和缓存行不命中率,进而提升内核整体性能。 对于想成为优秀CUDA内核编程者而言,掌握内存加载和优化的艺术至关重要。了解GPU多级内存的层次特点,熟悉线程协作与数据重用技术,同时具备调试内存瓶颈和性能剖析的能力,是不断提升内核性能的基石。 值得一提的是,虽然算力的提升也在推动人工智能前进,但现实情况是内存带宽和延迟问题更容易成为性能的“短板”。
未来的高性能CUDA内核设计必然是算力与内存效率的双重胜利,只有内存优化到位,才能不断释放GPU算力的最大潜能。 总结来说,内存优化作为高性能CUDA内核开发的重中之重,是推动人工智能计算性能升级的核心动力。通过合理规划内存访问、数据布局、线程调度与同步,充分利用GPU内存层级结构,开发者能极大提升深度学习模型的执行速度和资源利用率,使得下一代AI应用在规模与效率上更具竞争优势。