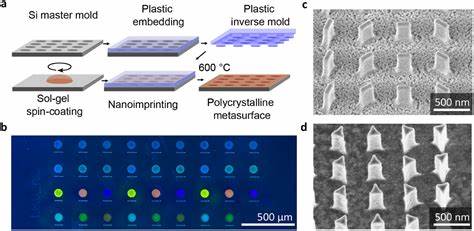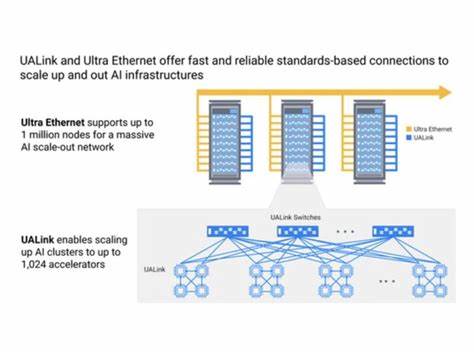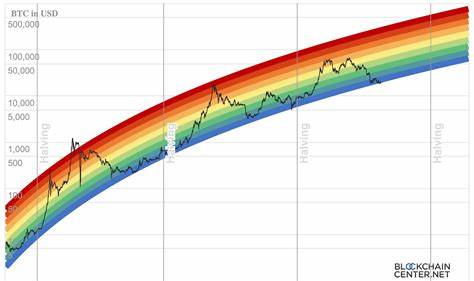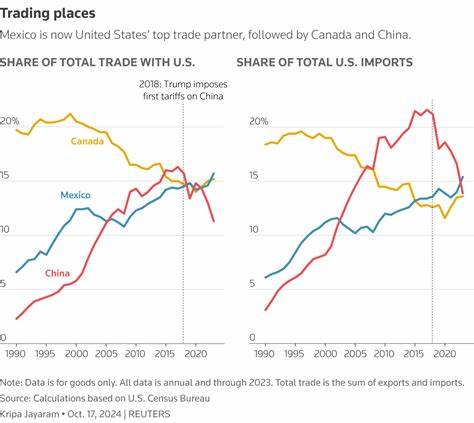
在数字时代,人工智能技术的飞速发展使大型语言模型(LLM)如ChatGPT、LLaMA和Qwen等得以广泛应用于聊天、写作辅助、客服及更多场景中。用户习惯于在人机交互中礼貌地说“谢谢”,然而,令人意外的是,这样一句简单的表示感激的词语,其背后竟蕴藏着显著的能量消耗。虽然在人与人之间,礼貌用语是交流的润滑剂,但在机器面前,礼貌并非功能必需,反而为能源带来了额外负担。本文将全面解读向大型语言模型表达感谢所带来的能源成本,深入理解其背后的技术机制及对未来AI应用场景的深远影响。 首先,需要明确的是,大型语言模型的运行原理决定了每一次回应都需要耗费大量计算资源。无论对话内容是复杂的提问还是简单的“谢谢”,模型都必须完成一次完整的推理过程。
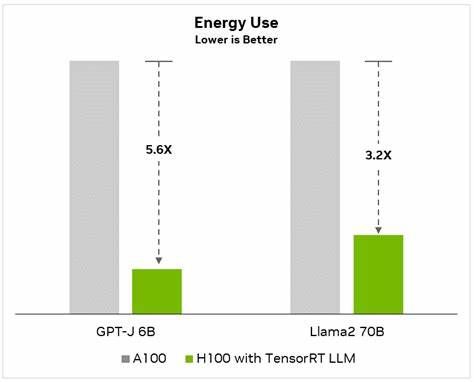
这意味着即使只是短短几字,模型也要通过数十亿甚至数百亿参数进行计算,激活深度神经网络的推理链,进而生成回复。与人类不同,语言模型不会记住之前的对话内容,除非刻意保存信息,因此每一句“谢谢”都被当做新的输入独立处理,无法利用“记忆”减少重复计算。 对于技术细节来说,使用的是如NVIDIA H100 GPU这样的高性能硬件进行推理。通过对数万个包含终结“谢谢”的对话数据进行研究,发现LLaMA 3–8B模型对每个“谢谢”响应的平均能量消耗大约为0.245瓦时,其中GPU部分消耗达到0.202瓦时,占整体耗电的绝大部分。以常见的5瓦LED灯为例,这相当于点亮这盏灯大约3分钟的用电量。尽管单次消耗看似微小,但当日常数以百万计用户的互动被统计后,其能量需求则呈几何级数增长。
不同规模的模型在能量消耗上表现出明显差异。研究显示,参数规模较小的模型执行效率更高,能量消耗较低。但大模型通常会给出更详细和冗长的回复,导致整体计算需求和能耗上升。例如,Qwen-14B参数模型相比0.5B模型,在处理类似“谢谢”这类简单输入时,耗电量提升近3至4倍。此外,模型生成回应的长度和对话上下文的复杂性也深刻影响最终能量需求。 模型规模并非唯一决定因素。
实际应用中,生产环境通常采用动态批处理技术,将多条请求合并并行处理,能显著降低每次推理所需的能耗,最高可减少10至15倍。然而,基础设施的能耗开销如冷却系统、网络设备和服务器待机时间,却难以避免地提高了整体消耗。此外,服务器所在的地理位置对冷却需求和电网碳排放强度也有显著影响。硬件配置优化和高效运算策略同样成为减缓能源成本的重要环节。 从环境可持续性的视角来看,大规模语言模型的能源消耗对全球碳足迹造成潜在压力。尽管单次“谢谢”的能耗数值微小,但累积效果巨大。
例如,大型模型在被数以百万计的用户频繁询问和互动中,若每次礼貌回应耗能高达1至5瓦时,则每日能耗可达到数兆瓦时,等同于数百个家庭的用电需求。由此可见,习以为常的礼貌用语在数字世界中的代价远超过人们的想象。 此外,随着AI技术向更复杂多任务方向发展,模型规模持续扩大,对计算能力和能源的需求也与日俱增。这不仅迫使企业加大对绿色计算和高效硬件的投入,也促使研究者探索低功耗模型设计和推理优化算法,努力降低AI使用的碳排放。比如,通过稀疏计算技术、模型剪枝和量化等手段,有望在保持模型性能的同时显著降低计算资源需求。 随着AI与人类生活的深度融合,我们也需要重新审视人机交互中的行为习惯。
虽然表达感谢和礼貌显示是人类文化的重要组成部分,但与当前的人工智能交互方式相比,或许可以发展出更加节能与合理的交互规范。例如,减少不必要的短语回复、优化对话设计,甚至在接口层面引入缓存和上下文记忆功能,从而避免重复完整计算。 总的来说,“谢谢”在与大型语言模型的对话中并不是免费的简单语言行为。它背后的计算链路要求高昂能源消耗,尤其在全球AI使用量持续飙升的背景下,能源成本和环保压力成为不可忽视的问题。理解这种成本能促进行业和用户更加理性地使用AI技术,推动绿色AI的发展路线。未来的人工智能不仅要更聪明,更需更环保,实现科技进步与可持续生态的和谐共生。
。