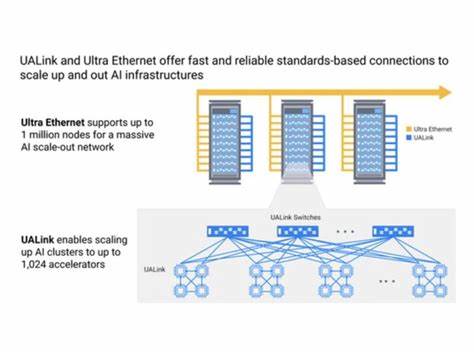
随着人工智能技术的迅猛发展,数据中心在处理日益庞大的计算任务时面临着前所未有的挑战。尤其是在AI训练和推理过程中,计算节点需要跨越单个芯片或模块边界,协调更多资源以加快处理速度和提高效率。当前数据中心内的通信协议在满足AI和高性能计算(HPC)日益复杂的需求方面存在不足,促使新协议的出现以填补空白。UALink和Ultra Ethernet便是在这个背景下应运而生的两种关键协议,分别针对数据中心计算架构的规模扩展(scale-up)和规模伸展(scale-out)提供具有针对性的通信解决方案。计算节点通常被视为计算的基本单元,它具备一定的处理能力、有限的内存和可能的加速器支持。在单一计算节点上运行高强度任务往往无法满足需求,需要跨节点协作分散工作负载,实现类似大型处理器的统一操作视图。
UALink专注于这种集群内部的资源统一与连接,而Ultra Ethernet则致力于跨机架或更大范围内的节点扩展,解决现有以以太网为基础的规模伸展架构在人工智能迁移中的性能瓶颈。现有的规模扩展协议往往依赖于专有技术,导致行业内重复投入资源及兼容性问题,并且传统的以太网虽广泛应用于跨机架通信,却因延迟和数据包重传机制等因素,在面对AI的高实时性和同步性需求时显得力不从心。UALink由UALink联盟于2024年末正式成立,目标是建立一个开放、高性能且专为AI加速器设计的统一扩展协议。该协议强调多加速器间的高速、低延迟内存通信,突破传统PCIe和CXL协议在统一地址空间和共享内存方面的限制。UALink通过三层架构实现其功能:物理层借助现有成熟的以太网物理接口降低实现难度,数据链路层负责每跳间的可靠数据传输,事务层则管理整个数据交换的复杂事务。由Synopsys、Cadence等多家领先设计公司参与,UALink专注于为GPU等多类型加速器提供高带宽的点对点连接,支持单一工作负载跨越数百到上千加速器的横向扩展,提升AI训练效率。
另一方面,Ultra Ethernet作为对传统以太网的增强协议,针对AI和HPC领域中的规模伸展过程提出创新性的改进方案。标准以太网面临的主要挑战之一是尾部延迟问题,即在同步计算时由于个别包延迟或丢包导致整体响应时间被拉长。Ultra Ethernet通过将传统以太网的层次结构上升至包含网络层(IP协议)和运输层,强化端点设备的拥塞控制、包重传及路径选择能力,极大地减小尾部延迟,提升数据中心东向和西向数据流的效率。此外,Ultra Ethernet引入了包括包级多路径传输(packet spraying)、链路级重传和信用基流控等技术手段,使数据传输更加灵活且容错能力更强,从而适应AI计算负载中频繁的双向数据交换特点。其设计理念在于保持对现有网络设备的兼容和渐进升级,不要求全新交换机硬件的立刻部署,以降低新协议落地的壁垒。两者均采用串行通信链路以减少信号线数量和复杂度,但这也带来额外的时钟提取和符号判别处理,平衡了实现复杂度和延迟性能。
UALink主要在机架内部形成大规模加速器池,统一内存和地址空间;而Ultra Ethernet则连接多个机架甚至数据中心,实现跨域扩展。它们共同构建了新一代数据中心的通信基础,对应不同层面的规模化需求。未来,两种协议预计将在2025年上半年陆续发布完整规范,向行业免费开放,推动数据中心领域的标准化。业内普遍认为,这两种协议不会取代PCIe或CXL,而是形成互补关系,共同促进AI和HPC工作负载的高效处理。鉴于AI作为驱动数据中心技术革新的核心应用,其对算力、大带宽和低延迟互联的需求持续增长,UALink和Ultra Ethernet的诞生代表着数据中心通信领域的重大突破。随着更多厂商开始采纳并集成这两种协议,预计在2026年以后,搭载UALink和Ultra Ethernet技术的服务器和加速器将逐步进入主流数据中心,带来更优异的AI训练及推理性能。
同时,双方联盟也在与IEEE、OCP、以太网联盟等国际标准组织保持沟通,努力避免标准分裂、保持生态系统的统一和兼容,确保未来网络技术的可持续发展。总之,UALink和Ultra Ethernet响应了AI计算需求的痛点,以开放和高效的方式促进数据中心资源的灵活组合和扩展,为人工智能和高性能计算领域注入了新的动力,助力实现更加智能、高效、可扩展的数据处理架构。随着技术的成熟和生态的完善,我们有望见证这一变革如何驱动未来智能计算的蓬勃发展,开创数据中心互联通信的新纪元。