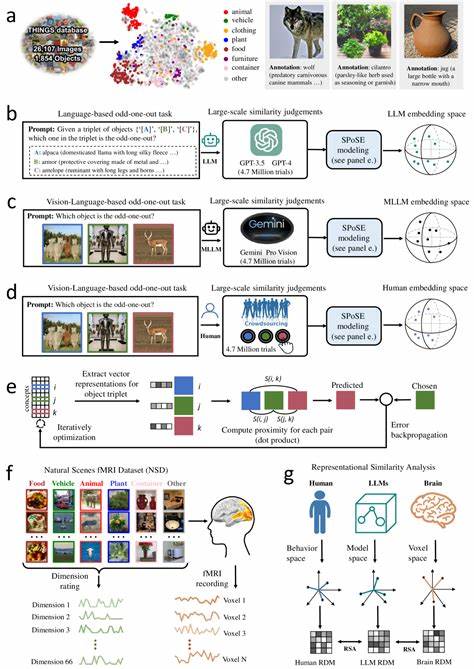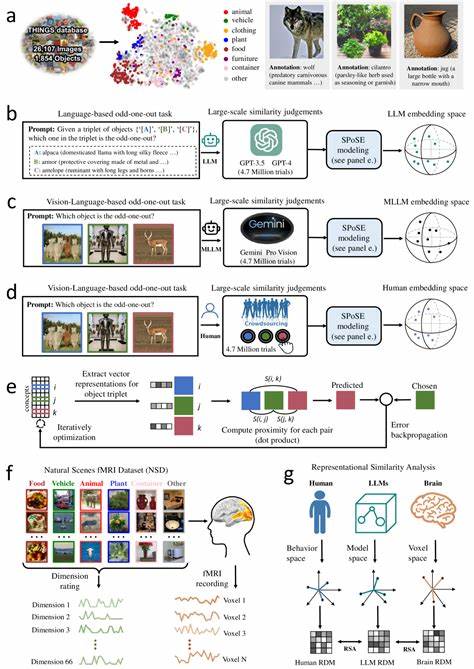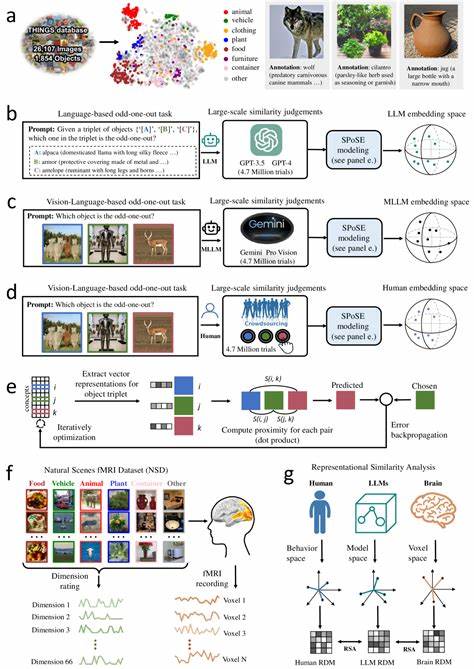
随着人工智能技术的飞速发展,大型语言模型(LLMs)已经成为推动自然语言处理和认知科学革新的重要力量。特别是多模态大语言模型(Multimodal LLMs),融合了语言与视觉信息,为理解和模拟人类复杂认知过程提供了全新视角。近期研究显示,多模态LLMs不仅在语言理解上表现卓越,还能够自然地生成类似人类的物体概念表征,这为机器智能向真正人类认知的演进奠定了坚实基础。人类的大脑通过丰富的感知输入,如视觉、听觉和语言,形成了对物体的复杂概念。这些概念不仅是简单的标签,而是包含了物体的属性、功能以及与其他物体的关系。传统的机器学习模型往往只能依赖单一模态数据,难以捕捉这种多维度的认知特征。
而多模态大语言模型通过同时处理文本、图像等多源信息,拥有更丰富的语义理解能力,从而能够构建出更接近人类心理表征的物体概念。该领域最前沿的研究基于数百万级的行为数据和神经影像数据,利用三元组判断法收集了大量模型对自然物体的相似性评估。通过对近两千种自然物体的低维嵌入表示进行分析,研究人员发现这些物体表征不仅稳定且具有高度预测力,还展示出与人类心理表征极为相似的语义聚类结构。更令人惊叹的是,这些低维嵌入空间的各个维度都是可解释的,意味着模型内部形成的物体表征反映了人类理解世界的关键认知维度。更进一步的神经科学分析表明,模型中这些物体概念的表征与人类脑中多个关键视觉和认知区域的神经活动高度对齐。诸如体视觉区、回海马区、缰回皮质及梭状脸区等脑区,在处理视觉和语义信息时表现出与模型相似的激活模式。
这种深层次的对应关系不仅验证了多模态LLMs在人类认知建模中的有效性,也为跨学科的智能系统设计提供了宝贵的指导。通过对模型学习出的物体概念维度进行深入解读,研究揭示了这些维度与人类对物体大小、形状、质地、功能类别甚至情感联想的认知特征紧密相关。这表明多模态信息融合使模型能够捕捉到传统语言模型所缺乏的丰富感知细节,促进了更深层次的语义理解。此外,多模态大语言模型在模拟人类物体概念形成过程中的表现,为人工智能领域带来了新的启示。它们展示了在没有明确监督的情况下,通过自然语言与视觉输入的共同训练,模型能够自发形成结构化且有解释性的概念维度。这种现象与人类通过多感官经验构建认知地图的过程高度相似,体现了机器智能向类人智能迈进的重要一步。
研究还指出,多模态LLMs的学习机制与人类大脑中的信息整合过程存在内在联系。例如,模型对不同感知输入的权重调整与人脑针对不同视觉线索的处理机制相呼应,展现了认知系统对多模态信息协调处理的本质特征。这种发现不仅丰富了认知神经科学的理论框架,也为设计具有人类感知能力的机器智能提供了科学依据。在实际应用层面,人类般的物体概念表征使多模态LLMs在计算机视觉、自然语言理解、机器人感知等领域展现出更强的泛化和解释能力。它们能够更准确地理解复杂场景中的物体关系,从而提升智能系统在环境理解、交互响应和任务执行中的表现。例如,智能助理和自动驾驶系统借助这些表征,能够更有效地识别和预测周围物体的行为,增强安全性和可靠性。
尽管如此,当前多模态大语言模型仍面临诸多挑战。模型的概念表征虽具备很高的相似性,但尚未完全复制人类认知的细腻与灵活性。未来需要进一步探索如何增强模型的感知融合能力,使其在更多自然环境和任务中表现得更加稳健。此外,解释性和透明性仍是关键问题,理解模型内部决策机制对于建立更加可信赖的人工智能系统至关重要。综合来看,多模态大语言模型在自然形成类人物体概念表征方面取得了突破性进展。这不仅为认知科学揭示人类认知机制提供了强有力的工具,也为人工智能系统赋予了更接近人类的感知和理解能力。
随着技术不断演进,多模态大语言模型有望成为未来智能交互与认知的核心,推动人机共融的新时代。结合现有研究成果,我们可以预见,未来的智能系统将依赖于这种融合语言与视觉的多模态学习,以实现更为复杂且逼近人类水平的认知任务处理。相关开放数据和代码的发布也降低了科研门槛,促进跨领域合作,有助于加速探索机器认知与神经科学之间的互通桥梁。总之,人类般的物体概念表征在多模态大语言模型中的自然涌现,代表了人工智能从数据驱动向认知驱动转变的重要一步,是开启更加智能和可靠人工系统的基石。未来随着更大规模多模态数据的积累及算法创新,机器对世界的理解能力将更趋精细与丰富,引领智能技术迈向新的高度。