在大数据时代,关系型数据库依然是企业数据存储与管理的基石。无论是内容推荐系统、流量预测,还是广告反作弊和其他关键信息服务,都离不开多表关系数据的有效分析。谷歌研究团队针对传统机器学习模型难以充分利用复杂关系结构的难题,创新性地提出将关系表转换为图结构,构建通用的图基础模型,开辟了数据智能的新路径。关系数据库是由多个相互关联的表格组成的网络,每张表代表一个实体类别,表中的每条记录对应图中的一个节点,表与表之间通过外键建立关联形成有向边。传统的决策树等机器学习算法难以发挥关系表中节点间复杂联系的潜力,往往只能孤立地处理单张表格,忽略了跨表关系的重要信息。与此同时,图神经网络(Graph Neural Networks)在处理图结构数据中表现出色,但其训练往往依赖于固定的图结构,一旦面对全新的图形态和标签空间,就需重新构建模型,缺乏泛化能力。
例如,一个在百亿节点引用网络上训练的GNN模型,无法直接应用于用户交易或商品推荐的图结构中,必须重新训练,极大限制了模型的复用和推广。谷歌研究团队的图基础模型尝试打破这一困境,目标是设计出单一模型,可以直接在不同的异构关系图上推理,从电子商务商品图到学术引用网络,无需额外训练即可准确完成多种预测任务,如节点分类、链接预测及图层级判别。其核心理念是充分利用数据库的连接结构,在转换为图结构后,将每个记录视为节点,不同的表构成不同类型的节点,外键关系构成类型化边。节点属性作为节点特征输入模型,既涵盖数值型也涵盖类别型数据,甚至可以嵌入时间序列信息。通过统一将异构关系表转成单一的复杂图结构,该模型能够捕获跨表依赖关系带来的语义信息,提升预测的准确性和鲁棒性。实现真正通用的图基础模型面临两大核心技术挑战。
首先,图中的节点类型、边类型以及节点特征在不同领域变化巨大,缺乏固定词汇表或标识体系,导致传统基于硬编码的嵌入方法难以迁移。其次,如何设计模型架构使其不依赖于特定任务或数据分布,从而拥有强泛化能力,使得模型在没有专门再训练的情况下适应新领域的新结构和特征。这一难题促使研究者设计了具有高容量的神经网络架构——类似Transformer这样结构灵活、可处理顺序及结构化数据的网络,但不同于自然语言处理中的词汇切分,图结构中缺少统一的“token”定义,研究团队通过创新的特征交互编码方法,实现了不同表格特征之间关系的建模,突破传统的硬编码限制。实验证明,模型基于相对特征间的相互作用而非绝对特征嵌入,表现出远超以往模型的泛化能力。这种方法兼顾了节点自身属性和复杂关联信息,显著提升了模型在多表关系预测任务中的性能。谷歌强大的分布式计算平台和GPU/TPU集群为训练大规模图基础模型提供了坚实保障。
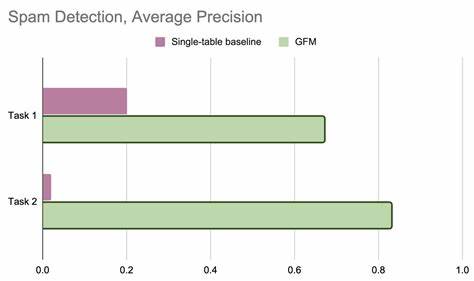
研究团队通过数十亿节点和数百亿条边的内部企业数据验证了模型的实用价值。面对复杂的广告垃圾信息识别任务,传统单表机器学习方法因缺乏跨表信息难以捕捉隐藏模式,表现受到较大限制。而图基础模型通过融合跨表关联结构,实现三倍至四十倍的平均精度提升,彰显了图结构信息在关系数据中的巨大潜力。图基础模型的崛起不仅推动了图学习与表格机器学习的融合,也为人工智能领域带来了多重启示。首先,数据的联结构造隐含着丰富的语义联系,充分利用这种结构将成为未来模型设计的重要方向。其次,通用性的基础模型能够大幅度降低模型重复训练和维护成本,提升研发效率。
未来,随着数据规模的不断扩大和模型设计的日益完善,图基础模型有望在智能推荐、金融风控、生物医药等多个领域实现更广泛的应用。随着对泛化理论的深入探究和多样训练数据的积累,图基础模型的性能还将迎来持续突破。综上所述,谷歌研究团队提出的图基础模型为关系数据的机器学习提供了全新的思路,将复杂的多表关系转化为图结构,结合高容量神经网络实现了跨领域、多任务的强泛化能力,并在实际大规模企业数据中实现显著性能提升。这一创新为数据智能时代的关系数据库分析注入了新的活力,也为人工智能技术的未来发展指明了方向。随着更多研究者和工业界加入探索,这一领域势必迎来更加激动人心的进展,推动数据驱动智能决策迈入崭新的高度。