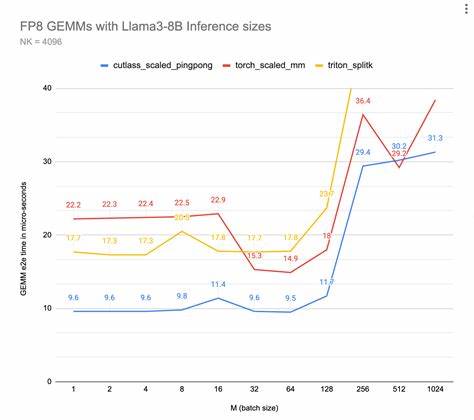
随着人工智能领域的高速发展,计算硬件的性能优化成为推动模型复杂度和效果提升的核心动力之一。在各种数值精度格式中,FP8(二阶浮点数格式)因其极高的运算速度和足够的计算准确度,成为业界关注的焦点。在现代GPU架构中,最新的研究和测试表明,当涉及FP8运算时,如果内核名称内含"cutlass"字样,性能提升幅度大约可达100 TFLOPS,这一现象引发了广泛关注和深入分析。 FP8作为一种精度格式,相较于更高阶的FP16、FP32,能够提供更高的运算吞吐率与能效比。这主要归功于FP8数据体积小,内存带宽占用低,以及更优的计算单元资源分配。尽管FP8的动态范围和精度有限,但对于许多深度学习任务,特别是训练和推理过程中的权重更新与计算,依然保持较好的性能表现和模型收敛效果。
Cutlass是由NVIDIA推出的CUDA模板库,专为优化矩阵乘法和卷积操作设计。它通过高度定制的代码生成器,能够在特定硬件平台上深度挖掘内存访问和计算单元的潜能,实现极致性能优化。当FP8格式的算子被映射到带有"cutlass"内核的实现时,由于Cutlass库自带的技术优化,如自动线程块划分、共享内存管理、混合精度计算策略等,使得计算过程中的资源利用率和指令执行效率大幅提升。 软件层面的优势还包括对线程并行度的精细调控,使得计算内核能够更好地适配底层硬件,最大限度地减少指令瓶颈和数据传输延迟。此外,Cutlass针对FP8计算的特定指导方针和优化技巧,令内存访问模式和算术操作更加高效,减少了算子执行的时钟周期数。 硬件层面,支持FP8的GPU架构在设计时考虑了低位宽计算数据路径和高速Tensor Core的高效调度。
结合Cutlass内核中的代码生成策略,能够充分发挥硬件Tensor Core的计算能力,进而实现高达100 TFLOPS的性能跃升。Tensor Core的专用混合精度单元以及先进的流水线设计,为FP8数值格式提供了理想的计算平台。 这种性能提升不仅限于单个矩阵乘法算子,而是在整个深度学习训练和推理任务中,都能带来显著的加速效果。大规模模型训练中,使用FP8与Cutlass内核的结合,显著缩短了计算时间,降低了能耗,提升了整体系统的效率,推动了更复杂模型的快速迭代和应用。 此外,FP8的应用场景不断扩展,涵盖图像识别、自然语言处理、推荐系统等多种深度学习模型。将Cutlass优化与FP8算元相结合,不仅提升了单次算子的峰值性能,也加强了整个网络的吞吐量,为开发者和研究人员提供了更加高效且灵活的算法实现方案。
尽管FP8与Cutlass内核的结合带来了显著性能优势,但也存在一些挑战。例如,FP8较低的数值精度在某些高精度需求的场景中可能导致模型训练的稳定性问题。为了应对这些挑战,深度学习框架和硬件厂商不断推出混合精度训练技术,结合动态精度调整和误差补偿方法,保证计算精度与性能的平衡。 从未来发展趋势来看,FP8加速技术将持续迭代,结合更加智能的调度机制和自适应精度选择策略,推动深度学习计算向更高效、更节能的方向迈进。同时,Cutlass等先进内核库的不断升级,也将为硬件性能释放提供有力保障。 综上所述,FP8在内核名称含有"cutlass"时性能提升约100 TFLOPS,既是硬件设计与软件优化协同作用的成果,也是深度学习计算迈向高效能时代的重要标志。
未来,随着相关技术的成熟和推广,FP8与Cutlass的深度结合势必成为加速人工智能应用的重要利器,为各行各业带来更快速、更精准的智能计算能力。