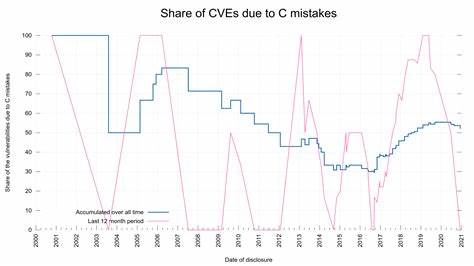
curl作为互联网数据传输的关键工具,其代码质量和安全性一直备受关注。作为一个用C语言编写的项目,curl自然面临C语言特有的一些安全挑战。近年来,curl团队对代码中的漏洞进行了系统的梳理与分类,特别关注那些因C语言编写特点而引发的安全缺陷,称之为“C语言错误”。本文将深入探讨这些C语言错误的特点、产生原因、漏洞影响以及应对策略,帮助开发者更好地认识和防范此类安全隐患。 curl的安全问题历来受到社区重视。经过漫长的安全事件积累,curl团队统计了多达167个由代码错误导致的安全漏洞,其中许多都与C语言的内存管理和指针操作密切相关。
C语言作为一个底层编程语言,提供了极大的灵活性,但也带来了诸如缓冲区溢出、内存泄露、未初始化内存读取及多线程同步问题等一系列潜在风险。这些漏洞不仅威胁curl的稳定性,更可能被恶意攻击者利用,造成远程代码执行、信息泄露等严重安全事件。 一个显著现象是在2017年至2020年期间curl中与C语言错误相关的漏洞数量大幅减少。curl项目负责人丹尼尔·斯滕伯格(Daniel Stenberg)指出,这一趋势源自多个因素的叠加。首先,团队引入了更完善的测试机制和代码审查流程,提高了代码的质量和安全性。其次,逐渐采用了辅助库和抽象如动态缓冲区(dynbuf)等来简化复杂的内存管理任务,减少手工错误。
最后,开发者通过规避某些易出错的代码模式、强化培训和经验积累,不断提升编写安全代码的能力。 然而,即便如此,C语言错误依然难以完全杜绝。一方面,curl的部分功能需要与外部库或系统接口直接交互,这些场景往往限制了安全抽象的使用。例如涉及字符串编码转换、网络协议解析等外部库调用时,数据边界和格式的完整性难以由curl代码完全控制,仍存在缓冲区访问越界等风险。另一方面,历史遗留代码与新老代码混合的开发模式,使得部分旧代码难以重构,从而延续了一些潜在的漏洞隐患。 社区讨论中曾提及是否将curl代码迁移到C++或Rust等更安全的语言能根除这类问题。
然而curl团队普遍认为,语言本身并非万能良方。正如斯滕伯格所言,C++同样可能出现类似的内存管理错误,而Rust虽能提供诸多安全保障,但完全用Rust重写curl在现实中面临巨大工作量和兼容性挑战。更重要的是,精进编码规范、增强测试覆盖、引入安全工具和静态分析更为实际和有效。 分析具体漏洞案例可以更清晰地理解curl中C语言错误的表现。例如在某些版本中,基于指针算术导致的越界读取使得程序访问了未授权内存区域。这种错误通常因对字符串边界判断不足或未正确检查外部数据长度引起。
又如动态缓冲区的使用限制使得部分函数依赖传统的字符数组操作,增加了缓冲区溢出的风险。对于这些问题,curl开发者采用了多种对策,包括加强边界检查、重构为更安全的接口、引入自动化模糊测试,意在未雨绸缪防止类似漏洞复发。 归根结底,curl项目中出现的C语言错误反映了底层编程中内存安全管理的复杂性和挑战。由此带来的教训对广大使用C语言开发网络应用的团队具有重要借鉴意义。安全意识和工程实践应双管齐下,利用先进工具监控潜在风险,并通过学习优秀开源项目经验不断提升自身能力。curl团队对这些漏洞的整理和公开,有助于推动安全文化建设,使社区整体得以受益。
未来,curl项目仍将持续加强安全研发投入,继续优化代码结构,并探索更多自动化检测手段,同时欢迎社区贡献测试用例和补丁。只有持续付出努力,才能在C语言带来的灵活性与安全稳定之间找到最佳平衡,保证curl作为互联网基础设施的重要角色安全可靠运行。 整体来看,curl中C语言错误的出现与其系统性的使用C语言以及功能复杂度密切相关。通过严谨的开发流程、现代化的辅助抽象以及社区协作,漏洞数量虽已大幅下降,但防范内存相关安全风险依旧是长期且持续的课题。对所有C语言开发者而言,curl的经验提供了宝贵参考,提醒不仅要认识语言的威力,也要规范使用,提升软件安全品质。