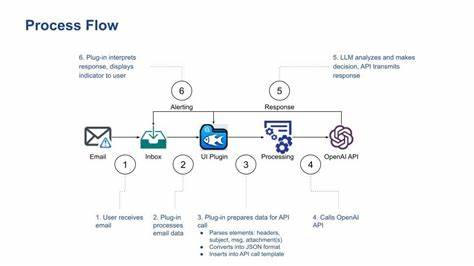
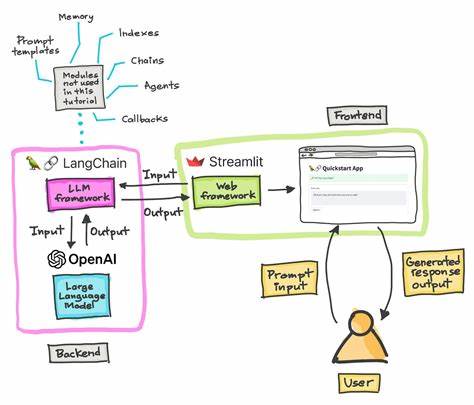
在自然语言处理(NLP)领域,语言模型的性能往往依赖于对语言内部结构和统计规律的深刻理解。随着以GPT-3为代表的生成式语言模型的兴起,研究者们开始更加关注模型的输入表示——也就是所谓的“符号”或“tokens”。这些符号是模型理解文本的基础,而其中的一个核心概念便是“熵”,它反映了符号分布的不确定性和信息量。尽管熵的数学定义已经明确,但关于符号频率如何影响熵的贡献,尤其是为什么某一特定频率的符号在熵贡献中达到最大,这仍是一个富有挑战并且尚未完全解答的问题。本文将围绕这一主题展开深入探讨。首先,理解熵的基本含义至关重要。
熵是信息论的基本概念,用于度量信息源的不确定性。简单地说,它告诉我们在一个给定的信息源中,平均每个符号携带多少比特的信息。符号的分布越均匀,它的熵越高,意味着信息的不确定性越大,需要更多的比特来编码。反之,如果某些符号极为常见,而其他符号罕见,熵就会降低,因为可以用更短的编码表示高频符号。对于自然语言来说,符号往往表现出非常复杂的分布,不同单词或子词的出现频率各不相同。更复杂的是,现代语言模型采用子词级别的tokenization,这种方法允许模型捕捉词根、词缀及词组内部结构,从而更有效地处理未登录词和罕见词。
像GPT-3使用的BPE(字节对编码)或类似的子词分割技术,虽然提升了模型的表现,但并非针对最优熵编码设计,而是基于实用和计算效率的折衷选择。深入分析符号频率对熵贡献的数学公式,可以发现一个极具趣味的结果:符号频率为约36.79%的符号对总熵的贡献达到最大。这个数字恰好是数学常数e的倒数,即1/e。这并非巧合,而是源自熵的定义和对其贡献的导数关系。当我们用符号出现的概率p描述其熵贡献时,贡献度由公式-p*log(p)确定。在这个函数中,当p等于1/e时达到最大值。
下面,让我们从理论和直觉两个角度解析这一现象的深层含义。首先,从信息论的角度看,熵衡量的是平均信息量。当某个符号的出现概率极高时,尽管它本身包含的信息少,但其频率大使其整体贡献不能忽视。相反,当符号极为罕见时,每次出现虽然携带较多信息,但由于频率低,其对整体熵的贡献也相对有限。位于中间的频率点意味着符号既不“平凡”也非“罕见”,能最大化贡献整个语言的信息不确定性。这折射出自然语言的复杂性:它既包含高频的功能词,也包含大量低频的专有名词和罕见用词,而这中间的平衡点则是熵贡献的“爆发点”。
其次,从数理统计的角度看,函数-p*log(p)的极值可通过求导数得到。对该函数求导后发现,当概率p等于1/e时,该函数取得最大值。这在数学上体现了e的独特性质:e是自然对数的底数,许多涉及连续增长和衰减过程的问题中都会出现e。令人疑惑的是,在深度学习和语言模型的实际应用中,符号分布却鲜有正好为1/e的场景,但这一数学结论仍提醒我们关注概率分布的非线性影响。这也引发了一个更深层次的未解之谜:为什么自然语言这样的复杂系统,其符号频率分布虽然遵循长尾规律,但在概念上却与e相关的数学特性产生了交集?学界目前尚未给出令人信服的解释,而这一点也引发了诸多探讨。另一方面,理解熵最大贡献的符号频率,对语言模型优化和tokenization策略都有现实意义。
由于模型按token计费,token数量直接影响使用成本;而更合理的tokenization能减少token数量,提高模型效率。因此,从理论层面探寻符号频率和信息贡献的关系,可为设计更有效的分词方法提供指导。例如,通过联合训练tokenization和语言模型,或许能靠近最优编码,在减少token数量的同时最大化模型性能。尽管目前主流模型的tokenizer大多基于启发式算法,如BPE或WordPiece,并未系统地将熵最优理论作为决策依据,但未来结合信息论的进展是可期的。最后,值得提及的是熵的广泛应用。无论是文本压缩、语音识别,还是自然语言生成,熵都作为衡量系统效率、复杂度和不确定性的工具发挥重要作用。
在实际工程中,理解和计算熵不仅能帮助优化编码方案,也可用于检测语言模型的困惑度(perplexity),间接反映模型对数据的拟合程度。总结来看,熵作为信息论的核心,揭示了符号频率与信息贡献之间微妙而深刻的关系。符号频率为1/e时达到熵贡献最大这一现象,不仅具有数学美感,也反映了语言本质的复杂性。尽管这一发现本身并不能完全解释自然语言的结构,但它启发我们进一步从基础原理出发,深入探索语言模型的输入表示方式和编码机制。随着技术的进步和理论的深化,相信未来我们能更好地解答长期以来困扰学术界和工业界的“熵之谜”,推动自然语言处理迈向新的高度。