随着人工智能和高性能计算的快速发展,矩阵乘法作为深度学习和科学计算中的核心操作,其运行效率对整个应用性能影响巨大。NVIDIA最新的Ada架构GPU凭借强大的Tensor Core单元,成为加速矩阵运算的利器。合理利用Tensor Core进行高速矩阵乘法,不仅可以显著提升计算速率,还能充分发挥GPU硬件潜能,接近理论峰值性能。本篇深入剖析了在Ada架构上实现高效Tensor Core矩阵乘法的关键技术与优化手段。 首先,Tensor Core的高效利用已经成为解锁NVIDIA GPU峰值性能的必备条件。Ada架构的Tensor Core支持m16n8k16形状的矩阵乘法,具备16×8×16的运算规模,能够在硬件级别进行大量并行浮点运算。
理解ptx指令中mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32的功能是优化的基础,它以fp16格式输入两矩阵A和B,输出累加为fp32格式的矩阵结果C和D。由于mma指令是warp级别操作,需要开发者精细划分线程合作模式,合理分配寄存器以实现最高吞吐。 针对矩阵规模为4096×4096的fp16输入和fp32累积的乘法问题,理论上计算量高达137.4 TFLOP/s,Ada架构RTX 4090在2520 MHz的boost时钟下,Tensor Core指令m16n8k16执行延迟约为32个时钟周期,相当于12.7纳秒。对此,核函数设计需最大程度避免内存访问瓶颈,保证算力单元持续供能。 初始的naive实现将多个Warp聚集于16×16线程块内,每个Warp计算32×32输出瓦片,虽然实现简单,但存在多个性能瓶颈。首先,线程们独立加载16位数据到寄存器,内存访问无序且无法向量化,导致全球内存加载效率低下。
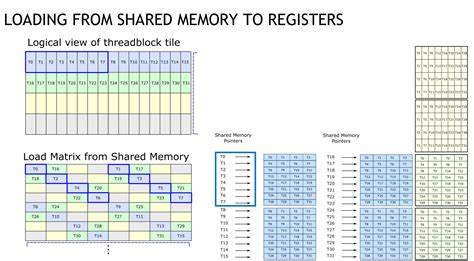
其次,shared memory访问缺乏充分优化,出现频繁的bank conflict,产生访存阻塞。最后,每个Warp仅完成单次mma指令操作,计算密度偏低,无法充分利用缓存与寄存器。 为突破这些限制,必须依照CUTLASS的经验采取多维度优化措施。引入基于uint4的128位宽向量加载极大提升了global memory访问效率,实现warps内顺序访问。为破解shared memory bank冲突,采用了permuted共享内存布局,将存储列索引与行索引通过异或运算映射,均匀分布内存访问,避免各线程竞争同一bank,极大减少内存访问延迟。 在寄存器层面,使用ldmatrix指令一次性加载多个8x128bit格式的矩阵片段,将permuted布局的shared memory数据以warp级别加载到寄存器,提升了warp内协作效率。
通过多级循环拆分,将(16×8)矩阵乘法精细切分成更小尺寸操作,增强并行度之余避免寄存器压力过大。 进一步改进中,开发者设计了n-stage异步流水线,充分利用ptx的cp.async指令从global memory异步拷贝片段至shared memory。此机制允许内存操作与算力指令重叠执行,减少因等待数据导致的停顿,提升整体利用率。实现方案包括建立多个共享内存循环缓冲区,提前预加载N-1阶段数据,循环更新预取窗口,并使用cp.async.commit_group和cp.async.wait_group精确控制复制流,保证数据安全到位后再执行mma计算。此举有效掩盖内存访问延迟,使流水线保持饱满。 除了流水线深度优化,增加每Warp计算循环中的输出瓦片数量也是提升效率的关键。
将每个线程块处理的输出矩阵从64×64扩大到128×128,意味着每个Warp在主循环中执行更多的mma指令,减少同步屏障次数与线程休眠时间,从而降低阻塞比率,进一步逼近硬件峰值性能。性能基准测试显示经过多轮优化后,自定义核函数最终达到了与cuBLAS相当的895微秒执行时间和153.6TFLOP/s吞吐量,实现了RTX 4090峰值性能的93%水平。 性能分析显示,之前共享内存的bank conflict及线程屏障等待占用的大量周期被有效解决。等待Tensor Core的硬件周期成为主要瓶颈,反映算法已经非常接近理论极限。尽管nsight-compute工具显示Tensor Core利用率仅47.3%,但这被认为是统计方法中延迟假设偏差导致的估计误差,实际硬件利用率更高。银行冲突的引入或消失还需进一步深究因cp.async指令启用共享内存访问路径的特殊行为而产生的指令级别冲突统计误差。
精细调试的过程也展现了对浮点计算数值准确性的高度关注。由于Tensor Core内部实现的累积时序和舍入误差,直接在mma指令中做累加可能导致结果偏差。通过将累积拆分,先不累加结果,再用CPU核心级别的浮点操作外部累计,能显著提升计算精度且仅带来轻微性能损耗,适用于对精度敏感的科学计算场景。 整体来看,在Ada架构上开发高效的Tensor Core矩阵乘法核函数是一项复杂且系统的工程,涉及低层PTX指令操作、访存策略优化、寄存器与Warp资源管理、流水线设计等多重技术突破。通过本次演化式优化,从朴素核函数性能的仅17.8%峰值跃升至超越80%甚至接近93%,展示了GPU深度编程的巨大潜力与挑战。 未来,随着CUDA和PTX的持续演进,尤其是sm_90指令集和更高级异步复制机制的推出,Tensor Core的利用效率还将被进一步挖掘。
同时,智能调度和图优化框架可能将这些底层细节自动化,令开发者专注于算法创新而非硬件细节。对已有代码的持续维护和性能对比分析,尤其借助专业分析工具如Nsight Compute,将是必不可少的手段。 总之,在高性能GPU计算不断成为AI及科学研究动力源泉的今天,深入理解Ada架构Tensor Core的工作原理及其高效编程方法,将对释放硬件潜力、提升应用性能起到至关重要的推动作用。通过合理设计矩阵乘法内核,采用permute共享内存结构、向量化访存、ldmatrix寄存器加载和n-stage异步流水线等关键技术,开发者可在实际任务中接近甚至超越官方高性能库的表现,助力低时延、高吞吐的计算需求。