在人工智能和自然语言处理领域,架构创新一直是推动技术进步的核心力量。近年来,一种名为H-Nets的层次化神经网络架构逐渐引起了研究者和实践者们的关注。作为未来序列建模的先锋,H-Nets不仅在理论层面展示了其独特优势,更在多语言处理、跨模态融合及长序列建模等实际应用场景中展现出卓越潜力。本文将系统梳理H-Nets的核心思想,深度剖析其直接应用、效率优化和未来发展方向,帮助读者全面理解这一前沿技术的意义与价值。 首先,H-Nets的本质是一种端到端的层次化网络,采用数据驱动的动态分段策略,实现对序列数据的多层次压缩与抽象。传统的序列模型,如果是自然语言模型,往往依赖于静态的分词或子词单元,存在一定的局限性,尤其面对没有明显语法边界的语言或数据模态时,分词的效果显著下降。
相比之下,H-Nets通过学习从数据中动态发现适合的分割点,构建更具语义意义的“令牌”,增强了模型的表达能力和适应性。 在多语言处理方面,H-Nets表现尤为引人瞩目。以中文及代码为代表的语言,传统分词或子词划分方法存在天然困难,导致模型在扩展性和性能上受限。H-Nets摒弃了预先定义的词汇表,而是通过层次化结构捕捉语言的内在规律,实现了更优异的扩展表现。实验数据显示,H-Nets在中文和编程语言处理中的规模化表现远超传统的基于分词的语言模型,表明其在多样性极高的语言环境中具有广阔的应用前景。此外,类似DNA序列这类科学领域的长序列数据,也是H-Nets潜力巨大的试验场。
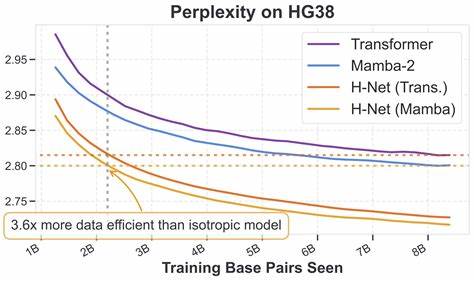
当前标准的序列建模方法大多以单一碱基为单位,缺乏对序列层次性的理解。H-Nets的层次化分段为这些数据带来了更自然的抽象方法,实现了显著性能提升,预示着其未来在生物信息学领域的广泛利用可能。 同样值得关注的是,H-Nets的理念和机制为处理连续值序列如音频和视频打开了新的可能。传统意义上的“分词”概念基于离散单元,并不适用于这些模态。然而动态分割策略可以在时间轴上识别重要的变化段,实现冗余数据的压缩,例如过滤静音段或静止帧,有望提升多模态模型的融合与分析能力。尽管这一方向目前仍需深入研究和实验验证,但其战略潜力不容小觑。
多模态融合一直是人工智能技术前沿的难题之一。不同模态数据往往采样率不同,存在时间步长的不匹配问题,例如文本以词或子词为单位,音频则以原始波形或压缩编码为载体。H-Nets通过动态块级空间的分割机制,具备天然的优势来协调这些差异,推动多通道、多模态模型实现更深层次的融合与理解。这种能力不仅有助于信息的同步处理,也增强了跨模态的推理能力,促进了智能系统在人机交互、自动驾驶、医疗诊断等复杂场景的应用。 从语言建模的核心任务看,H-Nets同样展现了巨大的优势。通过分层抽象,模型能够在更高语义层面捕捉语言规律,这不仅提高了语言理解和生成的质量,也为推理能力的提升提供了有效支持。
目前,尽管关于H-Nets的严格规模定律尚未完全确立,但已有的实验结果和理论推断均指向其在模型规模与性能间能够实现更佳的平衡,说明其有望成为下一代语言模型的基础架构。 架构的效率问题是衡量新技术能否大规模应用的关键因素。H-Nets固有的动态分段和层次结构在理论上与模型的质量提升紧密相关,而效率提升则是其潜在的附加收益。一个颇具启发性的比较是,H-Nets的解码过程与当前流行的“推测解码”(Speculative Decoding)技术高度相似。推测解码通过利用小模型快速生成草稿,再由大模型验证并修正,显著提升生成速度。而H-Nets则将这类机制内嵌进了网络结构中,避免了推测解码的额外复杂度。
换句话说,H-Nets的设计理念隐含地吸收并超越了推测解码,预示着未来推理效率将有大幅提升,且不必依赖复杂的推断技巧。 尽管如此,当前H-Nets在训练和推断阶段仍面临着不小的工程挑战。动态分段导致的数据加载和负载均衡问题,需要精心设计的数据管线和硬件策略来缓解。虽然目前实现的训练速度相比传统模型稍显缓慢,但像混合专家模型等近年来的研究成果为优化其训练效率提供了丰厚的经验借鉴。推断方面,H-Nets与现有推理框架的兼容性和高效实现仍需进一步探索。综合来看,架构本身的理论优势强烈支撑投入必要的研发力量,以克服实践落地的各种难题。
H-Nets的兴起也预示着架构研究的复兴。现代序列模型中,对层次化结构的探索热度持续不减。诸如本地块聚合的稀疏注意力、基于二叉树层级的对数线性注意力等,均尝试通过注入层级思想提升模型表达。但这些方法往往受限于静态树形结构或硬件约束,缺乏动态性和灵活性。相比之下,H-Nets层级结构的全局网络设计,辅以动态适应机制,拥有更强的表达力和可控性。未来的趋势或许是通过深度嵌套的层级结构,实现序列长度上的线性计算与状态大小的对数或多项式规模平衡,极大提升大规模序列任务的建模能力。
在处理长上下文任务时,H-Nets也展现出独特优势。传统模型由于计算和记忆瓶颈,对长序列的建模能力有限。通过分层压缩和信息抽象,H-Nets能够有效缩短序列长度,在较低层级保持高分辨率信息,同时在高层级执行长距离依赖关系的捕获。这种设计或许能减少对全局注意力机制的依赖,从而以更低的计算复杂度完成复杂的长序列分析,推动自然语言理解、视频分析和基因序列解读等领域的创新。 混合模型的构建也是H-Nets的创新点之一。通过在不同层级灵活组合线性模型与二次复杂度的注意力机制,H-Nets可以在保证计算效率的同时兼顾表达能力。
线性层负责高分辨率的局部特征捕捉,二次复杂度层则专注于高层语义关系的精细建模,这种优雅的分工有别于传统简单交织的混合策略。未来,像状态空间模型(SSMs)这样的线性序列模型,有望成为H-Nets字节级接口的核心部分,推动语言模型评测标准向底层字节级任务延展,实现更全面的能力评估。 总的来说,H-Nets的发展处于序列建模的“荒野”阶段。设计中存在大量不确定性与潜在改进方向,如何简化路由机制、如何扩展更深层次的层级、如何结合新兴的序列原语,都是未来研究的重要课题。然而,正是这种探索的开放性与丰富的变化空间,预示着H-Nets在不断迭代中将迎来迸发式的创新。 纵观现有人工智能系统,层次化处理已经无处不在,但多以显式的流水线形式存在,如分词与语言模型的耦合,推测解码中草稿模型与验证模型的交互。
H-Nets的意义在于将这些显式分离的组件,整合成统一的端到端结构,既简化了模型设计,也提升了训练与推断的有效性。这与业界对“大模型”的发展方向不谋而合,即追求通过端到端深度学习凝练复杂流程,实现更强大的泛化与适应能力。 未来若能克服训练和推断中的工程难题,打造出高效、可扩展的H-Nets实现方案,将极大促进各种序列任务的性能提升,真正引领大规模智能模型迈向新纪元。研究者和工程师们正站在这一变革的风口,希望通过不断创新与合作,共同开拓序列模型的未来疆界。









