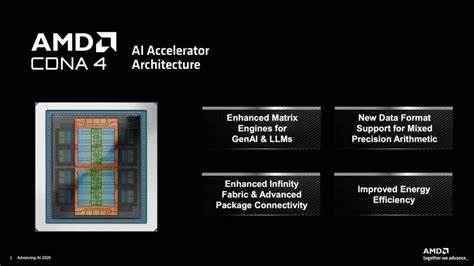
随着人工智能技术的飞速发展,AI计算硬件的性能和效率成为行业关注的焦点。AMD近日在其2025人工智能推进大会上正式发布了新一代高性能AI加速器——MI350X和MI355X,这两款GPU产品不仅在性能上实现大幅跃升,更在能效表现和架构设计上表现亮眼,进一步巩固了AMD在AI计算领域中的竞争地位。AMD强调,这一新品系列的推出将有效助力数据中心和企业客户实现算力升级,提升人工智能训练与推理的效率和精度。【创新架构加持,性能飙升】MI350X和MI355X基于AMD全新CDNA 4架构,配置上采用了先进的台积电N3P工艺制造,芯片内整合了多达八颗加速计算单元(XCD),总共256个计算单元(CU),相比上一代MI300X的1530亿晶体管,新款芯片的晶体管数量提升至1850亿,增加了约21%,为复杂AI模型运算提供了坚实的硬件基础。两款GPU均配备高达288GB的HBM3E高速显存,内存带宽达到令人瞩目的8TB/s,支持FP4和FP6等新兴低精度数据类型,极大提升AI推理的吞吐和能效表现。得益于这些技术上的突破,AMD宣称MI350X与MI355X在AI计算性能较上一代产品提升达4倍,而在推理性能方面更是实现高达35倍的增幅,足以满足当前大规模语言模型(LLM)和各类深度学习任务对算力日益增长的需求。
值得注意的是,MI355X专为液冷系统设计,功耗最高可达1400W,满足顶级性能追求的同时通过高效散热保障稳定运行,而MI350X则面向空气冷却方案,适合更多部署环境。两者在整体设计上保持一致,便于用户根据实际需要进行弹性选型。AMD还特别优化了Infinity Fabric互联技术,连接带宽提升至5.5TB/s,有效减轻多GPU协同工作时的数据瓶颈。GPU间通过7条Infinity Fabric通道实现近1.1TB/s的总通信带宽,助力实现更高效的分布式训练和推理任务。提升节点级别的通信效率,AMD致力于解决规模化AI计算中最为关键的连接与扩展难题。多维度规格表现和性能对比同样令人关注。
对比市场主流竞争对手Nvidia的GB200和B200,AMD MI355X在显存容量上领先1.6倍,带来更大数据处理空间。FP64和FP32两项关键精度指标上,AMD取得了约2倍的峰值优势,而在AI主流应用更依赖的FP16、FP8及新兴FP6、FP4格式中,AMD的表现基本与Nvidia持平甚至略有超越,尤其FP6计算在FP4速率下提供的高吞吐成为差异化卖点。值得一提的是,MI350X在FP64矩阵计算性能上一代有所减半,但整体浮点计算表现仍较为均衡,反映出面向AI特定需求的重点优化方向。由于FP4和FP6在现代AI推理及训练中的重要性日益凸显,AMD的支持将为AI开发者提供更多灵活和高效的工具。产品设计秉承了封装创新理念,采用3D与2.5D封装技术融合集成XCD与IO Die,提升整体芯片密度及效率,而IO Die则简化为两块瓷砖以降低功耗,统筹性能与节能平衡。此外,32MB的Infinity Cache分布于每个HBM3E堆叠前端,极大降低显存访问延迟,优化内存层次结构表现。
集成PCIe 5.0 x16接口也保障了数据传输速度和兼容性,为服务器级应用部署提供便利。针对服务器应用形态,两款GPU均采用OAM模块形式,兼容行业标准UBB封装和OCP服务器架构,这一设计决策使得客户可快速替换和部署,缩短从采购到上线的时间。AMD提供了包括64个MI350X GPU的空气冷却架构和支持128个MI355X液冷GPU的高密度机架方案,满足不同规模和性能需求的客户选择。液冷平台则利用紧凑节点设计在单位空间中实现更高吞吐与能效比,保障数据中心投资的整体回报率。网络互联方面,AMD结合Ultra Accelerator Link (UAL)与新型Ultra Ethernet Consortium (UEC)协议,提供灵活可扩展的网络方案,兼顾大规模数据交换和延迟敏感的AI任务,彰显其对现代高性能计算芯片互联标准的深度耕耘。性能表现上,AMD在多款主流自然语言处理模型中进行对比,展示多GPU MI355X部署在具体推理任务,如Llama 3.1 405B版本,能实现较Nvidia四卡GB200配置高出30%的性能,八卡配置下与Nvidia B200整机架构性能持平甚至略微领先。
训练性能方面,AMD稳占与竞争对手持平甚至微弱领先的位置,表明其在AI训练领域的综合实力已跻身主流。一线AI应用如智能客服和生成式内容创作也得益于新芯片,AMD标榜MI355X在特定AI代理和聊天机器人工作负载中比MI300X提升4.2倍性能,而生成、摘要和对话语义理解等任务带来的性能增长则宽泛介于2.6到3.8倍。整体来看,AMD MI350X与MI355X不仅在硬件层面进行了大幅革新,更聚焦于解决AI数据中心性能密度与功耗的平衡,力求为客户实现更优越的性能价格比(PPC)和更低的总拥有成本(TCO)。此次发布也反映出AMD在推进AI专用硬件技术路线上的战略布局,结合先前的EPYC Turin处理器,可形成从计算到存储再到网络的全方位解决方案生态,助推客户应对日益复杂的AI模型和海量数据处理需求。未来,随着更多合作伙伴的加入和产品线持续丰富,AMD期待通过持续创新与开放合作打造更具竞争力的AI加速生态,助力科研、云计算及边缘计算等行业实现跨时代跃迁。总体而言,MI350X与MI355X强劲的性能提升和灵活的部署方案,将为人工智能硬件市场注入新的活力,推动AI应用更快速地落地与规模化发展,为智能时代的信息处理方式开启新的篇章。
。