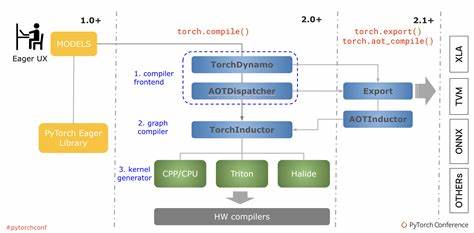
随着人工智能和深度学习的蓬勃发展,PyTorch作为领先的开源深度学习框架,备受研究者和开发者的青睐。而PyTorch强大的功能得益于其灵活且高效的后端架构支持,这些后端不仅包括CPU和GPU等硬件平台,还涵盖了针对于不同计算需求的专用库与优化策略。本文将全面解析PyTorch中的后端组件,揭示它们如何协同工作,加速深度学习的训练与推理过程,提升整体效能。 PyTorch后端的设计宗旨是提供一个抽象层,将底层硬件计算资源充分利用,给上层API调用带来高效的执行环境。后端涵盖了不同的硬件计算设备和优化算法库,例如CPU后端融合了Intel MKL、OpenMP、oneDNN(前身为MKL-DNN)等,在保障高效并行的同时,实现对矩阵运算、卷积等基础运算的加速。GPU后端包含了针对NVIDIA CUDA的支持,通过cuBLAS、cuDNN、cuSPARSELt等库,加速线性代数及稀疏矩阵计算,极大提升深度网络模型的训练速度。
在CPU层面,PyTorch通过torch.backends.cpu模块,识别CPU的具体功能集,包括AVX、AVX2、AVX512、VSX和SVE256等指令集扩展,这些指令集为向量化计算提供了硬件基础。利用这些指令集,PyTorch可以最大化地执行矩阵乘法、卷积等并行计算操作。在多核CPU上,结合OpenMP后端为矩阵运算和数据加载实现多线程并行,进一步提升效率。同时,MKL与oneDNN作为Intel的数学核心库,支持一系列高度优化的数值计算,并能灵活调度多线程和向量指令,成为PyTorch在CPU计算场景下的重要后端动力。 GPU是深度学习模型加速的主战场,PyTorch的torch.backends.cuda模块提供了丰富的功能来检测与管理CUDA环境,包括判断CUDA是否内建支持,控制TensorFloat-32(TF32)在Ampere及以上GPU设备上的使用,以及管理cuFFT计划缓存以优化傅里叶变换的性能。cuda后端允许用户通过配置优先使用不同的BLAS库,如cuBLAS、cuBLASLt,或在ROCm环境下使用hipBLAS等,以匹配实际应用的性能需求。
此外,线性代数操作可通过选择cuSOLVER或MAGMA优化,优化矩阵分解、求逆等常见数学运算。PyTorch还提供了FlashAttention等尖端技术的支持,结合SDPAParams等内部机制实现加速的缩放点积注意力机制,提升Transformer类模型的计算效率。 cuDNN作为CUDA深度神经网络库,是GPU端神经网络计算的基石。torch.backends.cudnn模块不仅提供了查询当前cuDNN版本和可用性的方法,还暴露了多个控制参数,比如允许或禁止TF32卷积计算,开启或关闭确定性算法以保证重复实验的结果一致性,以及动态调整benchmark参数以自动选择最快的卷积算法。通过这类精细设置,用户可以在性能与准确性之间灵活权衡。 专为稀疏矩阵及矩阵乘法设计的cuSPARSELt后端同样重要,它支持稀疏矩阵的控制和加速计算,提高稀疏神经网络的运行效率。
与此同时,在多头注意力网络领域,PyTorch引入了torch.backends.mha模块从内核层提供快速路径支持,极大缩短Transformer相关计算的执行时间。该模块能够动态检测条件并按照JIT编译优化路径执行,确保在满足输入约束的情况下展现高性能。 在苹果生态系统中,torch.backends.mps模块负责管理Metal Performance Shaders(MPS)后端,支持对M1及以上芯片上的GPU计算加速。通过判断是否内建和是否可用,该模块确保PyTorch能在Mac设备上高效利用MPS驱动的图形和计算能力。 值得关注的还有PyTorch对最优爱因斯坦求和(opt_einsum)的支持,torch.backends.opt_einsum模块能够检测并启用该第三方库,以动态规划优化多重矩阵乘积路径。该功能对计算图非常复杂的模型尤为重要,为张量合并操作提供显著的速度提升,同时减小内存消耗。
用户甚至可通过配置策略在“auto”、“贪心”或“最优”等路径策略间切换,进一步细化性能调优。 在一些特殊的神经网络加速器及英特尔Xeon处理器等硬件方向,PyTorch也在逐步开放诸如torch.backends.xeon等模块,为这些平台优化指令集使用和内存布局,以便利更广泛的计算生态整合。 一个关注点是PyTorch后端的可配置性和灵活性。开发者可以通过环境变量或者运行时参数,全局或局部控制后端行为。比如利用torch.backends.cuda.matmul系列布尔标志,调节是否允许TF32或者半精度减少精度的计算,或者调整cuFFT缓存大小与清理策略。这些配置允许用户根据具体模型大小、硬件性能以及计算需求,精细平衡性能和数值稳定性。
另外,PyTorch后端还支持丰富的调试与性能分析工具。MKL和oneDNN的“verbose”功能,可以只针对指定代码区块开启详细的性能日志,帮助排查瓶颈和算法选择。从整体架构上看,PyTorch将这些底层特性紧密集成,使得无论是研究人员调优模型参数,还是工程师部署大规模训练,均可有效利用硬件资源,提升AI应用的响应速度与效率。 随着深度学习算法的复杂化和硬件体系结构的丰富化,PyTorch后端也在不断演进。无论是对新兴的硬件平台如AMD ROCm、苹果M系列芯片的适配,还是对诸如FlashAttention和高效内存访问技术的支持,都体现了PyTorch生态对性能的极致追求。开发者可借助这些后端组件打造更加稳定、快速、精确的神经网络应用,推动人工智能技术向更广泛领域的深入应用。
综上所述,PyTorch后端是深度学习计算性能的核心保障。它涵盖了多种硬件平台和专业计算库,通过灵活的配置和高度优化的接口,将底层计算资源高效调度给前端API。理解和善用这些后端特性,能够极大提升模型训练效率和推理速度,为深度学习开发者和研究人员提供坚实的技术支撑和优化空间。未来,随着后端的持续迭代完善,PyTorch有望在深度学习领域中保持技术领先,为AI创新加速赋能。