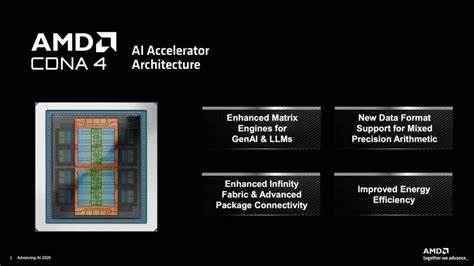
随着人工智能和高性能计算的不断发展,硬件加速器的革新成为推动技术进步的关键因素。2025年6月,AMD发布了新一代Instinct MI350加速器以及基于全新CDNA 4架构的创新设计,配合ROCm 7软件平台,为数据中心和AI开发者带来前所未有的性能提升和更便捷的软件体验。AMD此次发布的产品不仅关注硬件层面的高性能和能效,还着重优化了面向AI工作负载的低精度计算能力,进一步巩固了其在AI加速市场的竞争力。 MI350硬件设计采用了模块化芯片组的理念,结合先进的3D堆叠封装技术,采用台积电N3P工艺制程,提升了芯片的能效比和计算密度。MI350集成了8个XCD计算芯片,每个XCD包含32个CDNA 4计算单元,总计256个计算单元,这些计算单元经过结构优化,算力更加强大。相比前代产品,尽管计算单元数量有所减少,但每个单元的性能增进显著,因而整体加速器的计算能力能够达到甚至超过预期。
架构设计上,MI350取消了四个I/O芯片,转而采用两个更大面积的I/O芯片,涵盖更广泛的计算和内存拓扑结构,减少了跨I/O芯片的数据传输开销,极大提升了数据流效率。Infinity Fabric互联技术和全新的Infinity Cache系统则在提升芯片内部带宽和延迟方面发挥了重要作用,使大量数据可以快速在计算单元和内存之间流动,解决了AI计算中因数据等待导致的性能瓶颈。 为了满足现代大型语言模型和深度学习的计算需求,MI350进一步扩展了内存容量和带宽,使得更多数据能在加速器上近距离存储和处理,极大减少了数据传输延迟。此外,MI350还引入了对低位宽数据格式的强化支持,重点发展FP6浮点格式,与FP4浮点格式共同构成了新的计算引擎,针对AI推理中普遍使用的低精度计算进行了深度优化。这种硬件级别的改进不仅提高了计算效率,也显著提升了单位功耗的算力表现。 在软件生态方面,AMD重磅推出ROCm 7平台,旨在为MI350及未来的CDNA 4架构提供强有力的软件支撑。
ROCm 7通过更完善的驱动和库更新,确保开发者可以无缝访问硬件加速功能,同时简化了安装和使用流程。AMD正努力实现ROCm的“一键安装”体验,未来ROCm 7预计将通过pip工具轻松安装,极大降低了开发门槛。 值得一提的是,ROCm 7将开放支持更多操作系统和设备类型。AMD计划在2025年内将ROCm扩展至笔记本电脑,涵盖包括Red Hat EPEL、Ubuntu、OpenSUSE、Fedora等Linux发行版,甚至实现无WSL支持的Windows平台运行。这意味着搭载AMD Ryzen AI MAX+ 395处理器的用户,可以直接在Windows系统上运行ROCm,无需额外配置虚拟层,为AI开发和研究提供了极大便利。 基于MI350加速器的AI性能提升尤为显著。
AMD展示了基于MI355X液冷版本FP8计算性能与NVIDIA B200的对比,结果表明MI355X在低精度算力和内存带宽优势突出,符合现代大规模AI训练的需求。AMD的企业AI战略和AI Developer Cloud平台也同步推出,通过云端资源和软件服务助力客户快速部署和调优AI模型,打造完整的开发生态。 相较于上一代MI300系列更注重FP64高精度计算,CDNA 4架构针对AI领域将重点放在低精度计算优化上,体现AMD对当下人工智能需求的精准把握。无论是大型语言模型的训练效率还是推理时的性能表现,MI350均实现了显著提升,这为数据中心、科研机构和企业在AI计算方面提供了更具性价比的解决方案。 另外,MI350平台采用了OAM UBB(Universal Baseboard)标准8-GPU通用基板形式,为硬件扩展和整合提供高度兼容性。配合空气冷却的MI350X和液冷版本MI355X,用户可根据自身需求灵活选择方案。
液冷版本最高功率可达1.4千瓦,可支持多达128个GPU的规模部署,尽管空间需求较大,但极大提升了超级计算规模,满足了未来AI计算对大规模GPU集群的强烈诉求。 从硬件架构到软件生态,AMD此次发布的MI350和CDNA 4架构展示了公司在AI硬件领域的坚实布局和技术积淀。随着ROCm 7软件平台的不断完善,开发者能够更加便利、高效地发挥MI350硬件潜能,推动从实验室到生产环境的AI应用落地。未来随着更多芯片制造技术和AI优化算法的融合,AMD有望继续引领业内变革,为AI计算时代注入强劲动力。全面提升的算力表现、先进的低精度计算支持、强大的内存性能以及良好的软件生态是MI350和CDNA 4成功的关键,这些优势将加速人工智能研究与应用的广泛普及,为各行业带来深远影响。