在现代数据分析领域,Python 因其丰富的库生态和高效的处理能力成为数据科学家的首选编程语言。随着数据规模的不断增长和多样性的增加,如何清晰且美观地呈现数据成为分析工作的重要环节。传统的 Pandas DataFrame 虽然强大,但面对复杂且多维的数据,经常需要额外工具进行样式定制才能满足演示和报告的需求。近期受关注的 Polars 数据框结合 Great Tables 样式工具,为用户带来了前所未有的数据表格美化体验,极大提升了表格报告的可读性与专业感。 Polars 是一个为 Python 设计的高速多线程数据框架,具备极佳性能和表达灵活性。不同于 Pandas 主要采用行优先处理,Polars 内部使用列式存储,同时支持惰性求值优化,使其处理大规模数据时表现更为高效。
Polars 的表达式系统功能强大,用户能够以简洁优雅的方式构建数据筛选、排序、转换等链式操作。而在数据展示层面,传统方法通常需要先将 Polars 数据框转换成 Pandas,再借助 Pandas DataFrame Styler 进行样式设计。但这一流程存在显著限制,尤其是无法充分利用 Polars 表达式的潜力。 Great Tables 则创新性地将 Polars 表达式直接应用于数据样式设置中,允许开发者通过条件表达式灵活地标记、突出显示乃至加粗特定数据单元格。这种深度集成不仅减少了数据转换的开销,更令样式设计过程前所未有地直观和高效。 Great Tables 的使用起步极其简单。
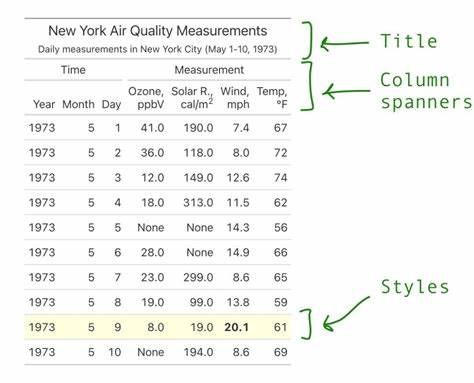
首先,载入所需的库和数据,将感兴趣的数据装入 Polars 数据框中,为展示做初步整理。随后,将数据框作为参数传入 GT 构造函数,生成一个可用于展示的样式对象。通过 GT 提供的多样方法,可以轻松添加标题和副标题,确保数据表的语义清晰且富有吸引力。 在样式应用方面,Great Tables 提供了丰富的接口。借助 tab_style 方法,用户可以为表格主体的指定行、列、甚至单个单元格设定颜色填充、字体加粗、斜体等多种视觉特效。例如,可以依据风速最大值所在的行,应用淡黄色背景高亮,同时将该数值加粗显示,使读者一目了然捕捉重点信息。
值得一提的是,这些样式条件均由 Polars 表达式精准定义,支持复杂逻辑组合。此外,Great Tables 支持列间分组标签的设置,即“列跨栏”,便于对相关列进行聚合标识,增强表格的结构感和可读性。用户可以通过 tab_spanner 方便地为“时间”、“测量”等相关字段进行归类,形成层次分明的列标签体系。配合 cols_label 方法,可利用 html 代码替换列名中的下划线和难懂缩写,实现格式优雅且信息丰富的列标题。结合这些工具,用户能够创建真正符合演示级标准的表格。例如,在处理纽约1973年5月1日至10日的空气质量测量数据时,通过 Great Tables 不仅展现了时间维度和多维测量指标,更通过样式凸显关键数据点,提升了直观可理解性。
Great Tables 目前专注于表格主体的样式,未来计划扩展支持包括标题、列标签等其他组成部分的定制,致力打造全方位的数据表格美化解决方案。与各种可视化工具(如 seaborn、plotly)配合使用时,Great Tables 能够为数据呈现提供不可替代的补充,进一步推动数据报告的表达力。 总体而言,Great Tables 以其对 Polars 表达式的深度利用,将数据框样式设计推向新的高度。它打破了传统工具对数据转换依赖的壁垒,提供了便捷、灵活且富有表现力的样式接口,让数据科学家和分析师能够把更多精力投入在数据洞察和故事讲述上。伴随着大数据时代对信息传递效率和视觉效果的更高要求,Great Tables 及其背后的 Polars 生态无疑为数据表格的未来描绘了广阔的蓝图。 本技术方案不仅适用于学术研究报告,也适合企业商业智能、金融分析、质量控制等各类行业报告制作。
借助 Polars 速度与表达优势、Great Tables 无缝的样式设计,用户能够轻松构建交互式且美观的表格界面,提升数据价值最大化。 随着社区的不断发展,Great Tables 的功能日趋完善,用户体验持续优化。对数据表格要求精细化和个性化的用户可以期待更多高级功能的推出,包括多层样式继承、动态数据驱动交互,以及更多文本和数字格式化选项。 综上所述,Great Tables 是 Polars 数据框不可多得的理想样式工具,造就梦幻级别的数据表格风格设计体验。它完美契合现代数据分析从数据处理到视觉表达的全流程需求,是数据工作者提升报告品质的有力助手。选择 Great Tables,意味着拥抱更智能、高效且富有美感的数据展示新时代。
。