在现代数据驱动的世界中,时间维度的数据管理变得尤为重要。无论是金融账目、医疗记录还是业务操作,理解数据随时间的变化不只关系到当下,更影响对历史和未来的洞察。双时态数据系统正是一种能够同时管理事实发生时间和数据记录时间的强大工具。虽然专业级的时态数据库系统广受欢迎,但对于资源有限的开发者来说,基于SQLite与Clojure搭建一个“贫穷版”双时态数据库系统,既经济又灵活,成为值得探索的选项。本文将带您深入了解该系统的设计思想、实现细节与实际应用,为您的数据项目带来全新视角。双时态数据库的核心理念在于同时记录两类时间:事件真实发生的时间和系统将该事件写入数据库的时间。
传统数据库多数只关注事件记录的当前状态,忽略了数据产生的历史背景及其变化过程。这使得在面对数据纠正、回溯分析和合规审计时显得力不从心。而双时态数据体系的引入旨在确保所有数据变化均可被追溯,以构建完整且可靠的数据时间线。SQLite作为一款轻量级、零配置的嵌入式数据库,以其灵活的类型系统和高效的存储机制成为理想选择。特别是在启用WAL(Write-Ahead Logging)模式后,SQLite可实现单写多读的并发访问,近似于Datomic等先进系统的行为模式。Clojure语言则以其函数式编程范式、不可变数据结构及强大的宏系统,为构建复杂的时态数据逻辑提供了坚实基础。
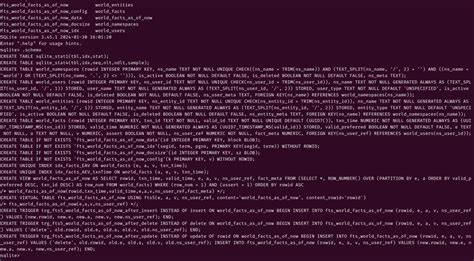
将两者结合,让开发者能够以极低的成本实现数据的时间化管理,并且保证系统的可维护性和可扩展性。为了模拟时间维度,核心设计将数据以Entity-Attribute-Value (EAV)模型存储,每条事实记录包含实体标识、属性名、具体值、事实的有效时间(事件时间)和事务时间(记录时间)。此外,事实的真假性通过一个布尔字段表示,解决数据状态因时间变迁而发生的矛盾问题。通过新增与修正记录的方式代替直接修改,保证了数据的不可变性和历史完整性,便于审计与回溯。为了解决数据冲突,设计中引入了UUIDv7作为全局唯一且时间有序的标识符,确保了在并发写入和多源事实汇聚时的可追踪性和一致性。优先级字段用于确立事实版本的优选状态,实现了“最后写入优先”或者“人工指定版本”等多种冲突解决策略,使系统更加灵活符合业务场景需求。
查询层面利用SQLite的视图功能,让当前数据库视图(Current DB)以查询的形式动态展示各实体属性最新且经过冲突解决的状态。组合窗口函数与索引,加速按时间维度的过滤操作,满足实时应用的性能要求。与此同时,扩展全文检索支持,通过SQLite内置的FTS5模块实现对文本属性的高效模糊检索,极大提升了应用的可用性和用户体验。Clojure端,利用HoneySQL库生成结构化SQL语句,避免手写字符串带来的错误,支持动态构造复杂查询,同时通过Specter库处理在内存中的数据结构视图,完成对数据库状态的业务逻辑加工和多维度分析。系统强调了命名空间和实体的唯一性约束,灵感来自Clojure的命名与隔离机制,保障数据模型的整洁与扩展潜力。用户、实体以及命名空间均应符合格式化的全局标识标准,防止数据交叉污染和权限混淆。
此外,系统采用append-only模式,所有操作都以追加事实形式出现,除非进行特殊且审计严格的变更指令。该设计极大增强了系统的可审计性、历史溯源能力和数据一致性,也方便了数据的异地备份和合并操作。由于系统构建在轻量级SQLite之上,部署简单,一般小型服务器或个人工作站便可承载业务需求。通过水平扩展数据库文件及应用逻辑,能够较好地适应多租户环境和分区存储策略。与Git类似的本地优先同步模式,利用事实的幂等性和全局唯一ID,实现了跨设备数据的合并与冲突解决,大大降低了分布式数据同步的复杂度。尽管该架构在性能和功能上不及专业时态数据库,但对资源有限并追求高自由度的开发者而言,是一个极佳的权衡选择。
面向未来,系统还可结合自动化测试及模式验证工具(如Clojure的spec或malli),确保数据写入完整可靠。更进一步,集成领域模型和典型业务流程的模拟,将为系统稳健性和实用性提供支持。复杂查询负载可通过应用层缓存和预计算视图进行优化,释放数据库压力。综上所述,基于SQLite与Clojure实现的贫穷版双时态数据库,既满足了基本的时间数据管理需求,又保持了极高的灵活性与可维护性。通过深入理解时间和事实的多维度特性,开发者能够构建出适应未来不确定性且足够稳健的数据系统。此类系统不仅适合小型创业项目和个人开发者,更为想要亲自控制全栈环境的技术爱好者提供了探索完整时态数据管理理念的实践平台。
随着技术的不断演进,结合本地优先架构和现代分布式协调机制,这种方案也有潜力衍生出更多创新和可扩展的应用场景。在数据“以时为王”的今天,对时间本质的洞察和管理能力,将决定每个数据系统的生命力和竞争力。选择合适的工具和设计,稳扎稳打打造贴合自身需求的双时态系统,或许正是迈向数据未来的关键一步。