近年来,人工智能领域尤其是大语言模型(LLM)的发展突飞猛进,带来了自然语言处理和生成能力的质的飞跃。然而,这类模型庞大的参数量和计算需求对硬件资源提出了极高的要求,限制了其在消费级设备上的广泛部署。为破解这一瓶颈,量化技术成为业界关注的核心方向。其中,GGUF量化技术作为一种后训练量化(Post-Training Quantization, PTQ)方案,凭借其独特的生态系统和高效性能,正在引领大语言模型推理效率革命。 GGUF量化技术本质上是一个涵盖多个组件的概念体。它不仅包含了GGML——一个专为机器学习设计的张量库,还融合了llama.cpp——面向CPU推理优化的开源大语言模型引擎,以及GGUF——用于存储量化模型的二进制文件格式。
该技术的核心目标是对已训练的类似LLaMA模型的权重进行位宽降低,从而大幅度减少模型所需内存占用和计算成本,提升推理速度,最终实现在标准消费硬件上的高效推理体验。 GGUF量化的诞生受到了先前多种量化方法的启发,包括GPTQ、AWQ、QLoRA以及QuIP等,但与这些源于学术机构的研究成果不同,GGUF量化更多得益于开源社区的力量,特别是由知名开发者Georgi Gerganov主导的持续迭代。尽管其功能强大且应用广泛,却缺乏官方系统化文档,这给了社区成员撰写非官方使用说明的机会,促进了技术知识的传播和普及。 了解GGUF量化生态系统的组成是掌握该技术的关键。首先,GGML作为轻量级张量运算库,支持多种数据类型和量化算法的高效计算,是后端推理的基础。其次,llama.cpp项目优化了大语言模型在CPU端的推理流程,使得即使没有高端GPU也能实现顺畅的推理体验。
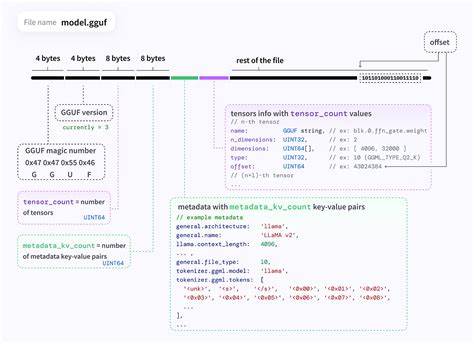
最后,GGUF文件格式承载了各种量化后的模型权重和元信息,确保不同环境下的兼容性和灵活性。 GGUF量化现实意义不仅体现在理论创新,更体现在实际效果上。通过合理减少模型权重的比特数,影响最小化准确率的同时,节省了超过50%以上的内存空间,令边缘设备和笔记本电脑等低功耗硬件也能运行大型语言模型。此外,相较于训练时量化,后训练量化避免了大规模重新训练的成本和时间,大大降低了模型迁移和部署的门槛。 然而,量化过程并非对性能没有代价。如何在压缩模型大小和保持输出质量之间找到最佳平衡,是当前研究和工程中的核心难题。
GGUF量化引入了诸如重要性矩阵(Importance Matrix)、k-quants与i-quants等策略来精细调整量化参数,保证模型尽可能精准地模拟原始浮点数权重的效果。通过这些智能算法,模型能够在大部分推理场景下维持高精度,同时享有显著的推理加速和资源节约。 技术实现方面,GGUF社区提供了丰富的命令行工具和实用指南,帮助用户便捷地执行各种量化任务。具体包括对不同层权重的选择性量化、实验不同位宽配置、生成且转换GGUF格式的模型文件等。此类工具不仅覆盖了初学者到高级用户的需求,也方便了性能对比测试和模型微调,让用户能够快速验证量化方案的影响并优化最终部署方案。 生态发展的另一个亮点是广泛的社区贡献和开源文化支持。
虽然GGUF官方缺乏正式文档,但社区成员持续维护并更新非官方文档库,通过GitHub等平台共享最佳实践、实验数据和技术剖析,促进了量化技术的横向传播。参与者不仅包括开发者和机器学习专家,也涵盖终端用户和爱好者,形成了良性的知识循环和生态共建氛围。 展望未来,GGUF量化有望引入更多智能化、自适应的量化算法,进一步压缩模型体积,提升推理效率。同时,随着硬件的不断进步和软件技术的日益成熟,GGUF生态将在移动设备、边缘计算等更广泛的应用场景打开新的可能。尤其是在个性化AI助手、智能翻译和内容生成领域,其便捷高效的推理能力将助力技术普及与应用落地。 总的来说,GGUF量化不仅是大语言模型技术发展的重要里程碑,更是推动AI技术普惠化的重要力量。
它通过系统化的后训练量化策略,打破了设备限制,降低了模型推理门槛。虽然尚处在快速迭代阶段,且官方文档匮乏,但借助社区的自主探索和协作,GGUF正在构建一个开放且高效的量化生态,赋能更多研究者和开发者打造智能应用。 深入理解GGUF量化技术,掌握其背后的理论和实践方法,将使AI从业者更好地驾驭大语言模型,推动创新应用的发展。未来,随着相关工具链日趋完善和规范,GGUF有望成为主流的量化方案,助推人工智能进入一个更加普惠、高效的新时代。