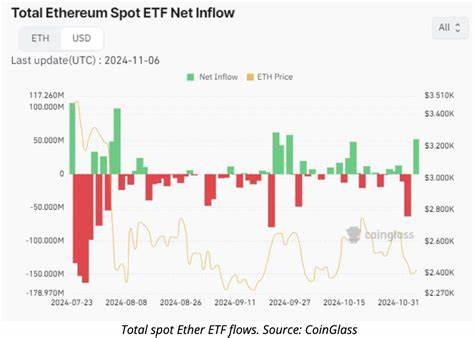
在软件工程的世界里,人工智能正被赋予越来越多的自动化任务,从自动补全到端到端代码生成,再到可以长时间执行的"代理"系统。衡量AI成熟度的一个常见标尺,是它能在多大程度上替代人类的参与:越能抽象掉人类的干预,越被视为更"聪明"。但当我们把智能的目标定义为把人抽离开来时,就可能把系统推向不可解释、不可控、且难以长期维护的方向。相反,一个以人类为中心、以人机共治为目标的设计,不仅更现实,也更有利于长期的效率、可验证性与组织知识积累。 为什么完全抽象人类是危险且有限的路径 把人类抽象掉的理念看似诱人:成本降低、无人值守运行、理论上的规模化。现实却揭示了多种问题。
首先,目标设定与约束总是由人来定义。一个长时间运行的"无监督任务"会遇到边界模糊、优先级冲突、依赖链变化等问题,这些都需要人的判断来调整。其次,可解释性与审计的需求在企业、金融、医疗等领域至关重要;完全的黑盒代理难以满足合规与责任追溯。再次,模型会犯错,错误传染效应在自动化流程中被放大,造成更高代价的连锁反应。最后,组织知识并非单向输入给模型就能长期保持,工程语境、历史决策、隐含约定常常需要人工维护与演绎,否则知识会漂移。 人机共治的核心观念:共养知识核心 替代抽象人的思路,应当被另一种思路取代:把AI视为增强人的工具,同时把人看作AI理解与成长的监督者。
具体做法是构建一个由人和AI共同维护的"知识核心",它以符号级别(例如函数、模块、接口、设计决策、约束条件)表示代码库的语义信息。知识核心既是文档,也是机器可读的语义图谱,能被模型检索、更新和审阅。它不是一次性生成的注释,而是随着每次提交、每次审阅、每次部署持续演化的活体资产。 知识核心的作用远不止传统文档。它可以作为提示工程的长期记忆,改变传统基于短期上下文窗口的提示方式,使AI在回答问题或生成代码时,能从精确符号节点开始检索上下文而非依赖全文模糊匹配。它也是审计与合规的记录器,记录为何某个设计被采用、谁负责决策、相关测试覆盖与风险评估如何完成,从而满足治理需求。
每个仓库的专属AI助手:更小、更专注、更可控 把通用大模型直接放在仓库中并不是长远最优解。一个更实际的路径是为每个代码库部署专属、精简且可离线运行的模型或模型组合。这些模型通过知识核心进行任务定制,理解仓库的边界、约束与历史变更。优势包括更低延迟、更好隐私保护、更便于合规审计与权限控制,以及更容易迭代与微调。 技术实现要点 要把上面构想变为可操作的工程实践,需要一套工程与数据结构的组合:首先要把源代码解析为语义符号单元,建立符号表与调用图。抽取抽象语义时可以借助AST、类型信息、单元测试与运行时日志来补充。
第二层是知识核心的数据模型,它应该支持富文本注释、决策元数据、责任人、变更历史与与外部依赖链接。底层储存建议结合图数据库与向量数据库:图数据库保存结构化的依赖与符号关系,向量数据库支持基于语义相似度的检索。第三层是检索增强生成(RAG)与本地微模型:当需要回答问题或生成代码片段时,系统先在知识核心与代码库中定位最相关的符号级上下文,再把这些上下文送入精简模型进行生成或推理。最后,在CI/CD流程中集成本知识产生的变更,触发人工审阅与自动化测试流水线,确保每一次知识核心的更新都伴随验证步骤。 工作流的演化:从临时提示到持续共养 传统的prompt-driven工作流片段化且难以积累。转向知识核心后,提示不再是短期策略,而是基于持久语义资产的调用。
例如,预提交阶段可以让AI为即将提交的改动生成新的知识条目草案,开发者在代码评审时同步审查并完善这些条目。合并时CI会验证知识条目的完整性与相关测试覆盖。部署后,运行时监控、异常日志与回归测试结果又可反向补充到知识核心,形成闭环反馈。这个闭环能兑现一个指数式增长的承诺:每一次人对AI知识的修正都会提高未来AI建议的质量,促成更有效率的协作。 治理、合规与可追溯性 人机共治不是放任自流,它必须带有透明的治理机制。知识核心提供了天然的审计线索:谁在何时以何理由修改了某个符号的语义,变更是否经过测试与审批。
对于敏感仓库,可以限定AI建议的权限级别,强制执行人类批准路径。日志应被设计为不可篡改或可追溯的记录,以满足法规与内部审计需求。此外,模型更新也需纳入治理,例如对微模型的训练数据、训练周期、评估指标进行版本化管理,防止盲目上线导致行为漂移。 可解释性与可调试性 相比纯黑盒代理,基于知识核心的系统更容易解释:当AI建议某段实现或架构调整时,系统可以直接展示其依赖的知识节点、相关测试结果与历史决策,从而让开发者理解"为什么"。在出现问题时,回溯到知识核心能帮助定位是模型误解、知识缺失还是测试覆盖不足。为提升可调试性,应当提供可视化的语义图谱浏览器、变更差异比对与模型建议溯源功能。
对传统与遗留系统的价值 大型机构的遗留系统(如银行中的旧式主机代码)存在知识稀缺与人才流失的问题。把知识核心概念化为每个系统的数字记忆,可以把少数经验丰富的工程师的隐性知识结构化并长期保留。为这些仓库定制轻量级本地模型,能让现有开发人员用更少的人力完成迁移、修复与扩展任务,从而降低运维风险与人才断层带来的损失。 部署与运维挑战 构建知识核心并非简单工程:语义抽取需要与代码静态与动态分析结合,向量化语义需要处理高维检索的精度问题,知识同步需要解决分支与合并时的冲突。运维上要考虑模型更新策略、数据隐私与备份、知识一致性与垃圾信息清理机制。合理的策略是从小规模试点开始,验证能带来可衡量的提升后再横向推广。
自动化测试覆盖与人类审查流程应成为不可或缺的风险缓冲。 衡量成功的指标 评价人机共治实践效果,需要明确的衡量体系。可用指标包括开发者的任务完成时间下降率、代码审查迭代次数减少、回归缺陷率降低、知识核心文档覆盖率、AI建议被采纳的比率与建议带来的性能或可维护性改进等。这些指标既能显示效率提升,也能帮助发现知识评价环节中的不足。 商业模式与组织采纳路径 企业内部工具化是首选切入点,通过在敏感但价值高的仓库中部署专属助手,快速体现ROI。之后可以把通用框架产品化,提供符号提取器、知识核心平台、向量检索与本地模型部署套件。
针对金融、医疗、能源等对合规性要求高的行业,提供加强版合规治理的企业方案可能具有溢价空间。对外市场的服务形式还包括咨询部署、迁移服务与持续知识管理运维。 未来展望:以人类为轴的指数增长 AI与人类不是零和博弈。把AI视为抽象掉人的工具,会在短期内获得自动化红利,但长期看会因信任缺失、知识漂移与监管问题而受限。反之,围绕"人类在环"的设计可释放更可持续的增长:人类把判断力、因果推理与价值观输入系统,AI把检索、推理与模式发现能力放大,两者形成正反馈。随着知识核心不断成熟,组织文化与工程实践会逐步吸收AI带来的效率与洞察,从而实现真正的指数式进步。
结语 在代码智能的发展道路上,方向比速度更重要。把AI当作替代人类的终极目标,会使我们在监管、可解释性和长期维护性上付出代价。以知识核心为纽带的人机共治路径,既能保护组织的知识资产,又能把AI的优势最大化用于增强人的能力。这种以人为中心的设计不是把AI弱化,而是把AI的力量引导到人类最需要的地方:决策的精确性、组织记忆的持久性与软件系统的可持续演化。软件工程的未来不在于"让人离开环",而在于建立更深的合作关系,让人类与智能系统共同养护代码世界。 。