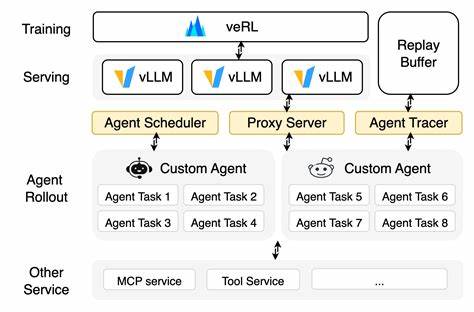
近年来,人工智能领域迎来了巨大变革,大型语言模型(LLM)不再满足于仅仅作为语言理解和生成的工具,而是在不断拓展其能力边界,成长为具备规划、自主决策和执行能力的智能代理。这些"拥有手脚"的语言模型不仅仅是思考者,更是行动者,能够与外部环境交互,完成复杂的多步骤任务。随之而来的是对强化学习(RL)系统提出了全新且更为复杂的设计要求。过去的强化学习框架多只针对单轮对话和简单文本生成优化,难以满足新型智能体在资源调度、环境交互和任务执行上的高强度需求。 这种转变带来的首要问题在于传统强化学习系统的局限性。以往的RL框架通常专注于"脑" - - 即语言模型的推理和理解能力,忽略了智能体"身体"的构建和调度能力。
当智能体需要调用代码执行环境、网络浏览器甚至是专用的计算资源时,单一的推理流水线便难以支撑整个任务流程,尤其是在要求并行处理大量智能体任务时,现有系统面临显著的性能瓶颈。 为了突破这一瓶颈,业界提出了"Agent Layer"(智能体层)的概念。该层作为强化学习框架与多样化执行环境之间的桥梁,专门负责任务的调度分配、环境管理以及数据采集。通过这种解耦架构,模型的推理与训练过程可独立于复杂的执行环境,同时Agent Layer还能统一收集和格式化智能体在执行过程中的状态、行动及奖励信号,为后续的训练提供高质量数据。这不仅提升了系统的灵活性,也极大增强了并行任务执行的规模和效率。 智能体RL系统在实际运行中面临的挑战极为多元。
不同类型的智能体可能需要多种隔离环境,如代码运行则依赖安全的Docker容器,机器学习实验则要求GPU计算资源的专属使用,网络搜索智能体则需稳定且快速的访问互联网数据。这些多样化需求导致系统调度复杂度飙升,传统框架难以有效支持大规模且异构的智能体并行执行,亟需更加精细的资源分配和环境池管理技术。 为解决环境管理和执行规模问题,业界领先方案普遍采用分布式任务调度架构。通过主从式调度器分配任务到不同的远程执行节点,可以实现数百甚至数千个智能体同时运行。容器技术如Docker和编排系统如Kubernetes成为基础设施的重要组成部分,它们提供了环境的隔离、快速启动和资源限制,保障任务安全性和执行效率。同时,中央环境池技术使智能体任务在不同运行周期间复用环境,显著降低了启动延迟,提高了整体吞吐量。
在面对智能体任务的长短不一和复杂多变时,系统设计同样要兼顾灵活性和高效性。少数超长任务可能拖累整个训练进度,导致昂贵的计算资源闲置。针对这一"长尾效应",异步架构被广泛采用,训练引擎和任务生成引擎分离运行,训练过程不必等待所有任务完成便能持续更新模型。部分任务截断保存状态的机制则能让系统切分长任务,分段处理并在后续迭代中继续执行,从而加快整体训练速度并提升资源利用率。 此外,动态负载均衡策略在提升多GPU环境的使用效率中发挥重要作用。通过监测每个GPU实时的可用缓存和计算负载,调度器能够智能地将任务合理分配,避免资源闲置和任务积压,提升整体系统的响应速度和吞吐量。
面向未来,具备行动力的强化学习系统不仅仅满足于当前的沙盒环境任务执行,更会逐步接入真实世界的计算资源,完成更为复杂的科学实验、工程设计和智能决策。这要求进一步提升算法的样本效率和奖励信号的有效性,推动多智能体协作及竞争机制的发展,甚至探索去中心化的智能体训练模式,使智能体能够持续从真实用户反馈中学习更新。 与此同时,具身智能体和机器人领域的发展也将加速强化学习系统向低时延控制、多模态感知和高效现实交互方向迈进,推动AI从虚拟环境走向实体世界的深度应用。 总体而言,当大型语言模型从单纯的"思考者"转变为具备"手脚"的全能智能体,强化学习系统的设计必须创新并适应这一范式变化。解耦训练推理与执行环境、统一数据接口规范、多样化分布式环境管理以及异步高效的训练流水线,是当前及未来智能体强化学习成功的关键基石。随着相关技术和方法的不断成熟,未来的智能体将更加自主、高效,真正成为解决复杂现实问题的强大助手。
。