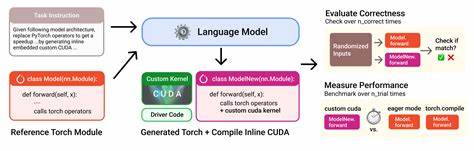
近年来,人工智能和机器学习领域取得了飞速发展,大型语言模型(Large Language Models,LLMs)凭借其强大的自然语言处理与代码生成能力,正逐渐渗透到各个技术领域。GPU作为支持深度学习和高性能计算的核心硬件,CUDA编程因其高效的数据并行处理能力而备受关注。然而,编写高性能、架构感知的CUDA内核代码一直以来都被视为一项技术门槛极高且耗时的任务。面对复杂的硬件细节、线程层次管理以及性能调优要求,传统的手工代码编写不仅效率低下,也难以充分发挥GPU的计算潜力。近期一项名为CUDA-LLM的创新研究,突破了大型语言模型在生成CUDA代码上的限制,提出了一套结合特征搜索与强化学习的框架,有效自动生成并优化CUDA内核。这种结合了人工智能与性能优化技术的方案,正为GPU编程领域带来革命性的变革。
该框架名为Feature Search and Reinforcement(FSR),其核心理念是通过交互式的搜索与强化学习来共同优化代码的编译结果、功能正确性和运行时性能。首先,LLMs利用海量的代码与硬件知识生成初始的CUDA代码。随后,FSR对生成的代码进行严格的测试,确保语法和功能的完整性,排除潜在的错误风险。最为关键的是,FSR评估代码在目标GPU上的实际执行延迟,并以此为反馈信号,以强化学习机制逐步优化代码结构,充分挖掘硬件潜能,达到性能极致。这一方法不仅保证了代码的正确性,更在性能上实现了显著提升。在涵盖AI应用和计算密集型算法的多组测试中,经过FSR优化的CUDA内核相比于一般人类编写的相应代码,性能提升最高可达到179倍。
如此巨大的速度突破表明,LLMs结合智能强化优化机制,有望成为GPU硬件专用程序设计的强力工具。传统CUDA编程往往依赖于开发者经验进行手动优化,包括线程划分、内存访问模式调整、共享内存利用等细节。随着硬件架构的多样化和复杂化,这些优化工作愈发繁琐且容易出现细微失误。CUDA-LLM框架通过自动生成高质量的代码旁及其基于具体硬件进行的迭代优化,大幅降低了开发难度和时间成本,为GPU应用开发者提供了灵活且高效的解决方案。此外,该方法的普适性也值得关注。FSR框架不仅适用于单一类型的CUDA任务,还涵盖了多种计算场景,包括矩阵运算、卷积神经网络、图算法等,展现了较强的泛化能力。
随着模型规模与训练数据的不断扩展,未来生成的CUDA代码在更多应用场景下实现性能引领成为可能。从产业角度来看,自动化编程与智能优化技术的结合,恰逢GPU计算需求爆发的关键节点。无论是云计算服务提供商,还是专注于人工智能推理与训练的企业,都将从自动生成高效CUDA内核中获益显著。它不仅能提升计算资源利用率,减少人为调试时间,还能加快产品迭代周期,提升整体竞争力。长远来看,这种技术推动下的自动优化GPU编程,或将促使硬件设计与软件生成形成更紧密协同,开启硬件-软件共进的新篇章。值得注意的是,CUDA-LLM的成功并非偶然,而是基于对CUDA编程关键特性的深刻理解和对LLMs生成能力的精妙运用。
FSR通过结合编译特征搜索和基于执行性能的强化反馈,使得纯语法层面生成的代码能够突破性能瓶颈,真正实现硬件级别的优化。同时,严格而多样化的测试用例保障了生成代码的功能正确性,避免了潜在的计算风险。未来,随着硬件架构不断迭代更新,GPU并行计算将趋向更加复杂。LLMs与自动优化方法的结合不仅适用于当前CUDA编程,也为其他领域的硬件感知代码生成提供了有力借鉴。例如FPGA编程、专用AI芯片代码自动生成等场景,都将受益于类似模型驱动的性能调优技术。总的来说,CUDA-LLM提出的基于特征搜索和强化学习的自动代码生成与优化框架,为解决GPU编程中的架构感知与性能关键问题开辟了新途径。
通过智能化手段实现高性能CUDA内核自动生成,不仅提升了开发效率,还带来了极为显著的性能改进。未来,随着人工智能技术的持续突破,这类跨领域融合创新将不断涌现,为科研与工业界的GPU编程注入强大动力,推动高性能计算进入全新阶段。









