正则表达式作为编程领域中处理文本匹配和模式识别的重要工具,长期以来以其简洁强大的表达能力获得了广泛应用。然而,随着正则表达式的不断演进,诸如反向引用(backreferences)、递归、条件语句以及边界断言(lookaround)等复杂特性逐渐成为必要支持,挑战了传统正则引擎的效率极限。特别是反向断言中的反向断言(lookbehind),在业内以往多依赖回溯机制实现,极易导致正则匹配出现指数级别的时间复杂度,给性能和稳定性带来严重隐患。近期,发表于2024年PLDI会议的《JavaScript正则表达式的线性匹配》论文揭示了一种全新的思路,证实捕获无关型lookbehind完全可以在线性时间内进行匹配,大幅缓解了传统回溯方法的性能瓶颈。基于此理论,谷歌开源的高速正则引擎RE2成功融入了这一算法,成为行业中首批支持线性时间捕获无关lookbehind的主流引擎之一,标志着正则表达式处理进入了一个全新的阶段。RE2引擎提供C++语言的API,兼具线程安全及高性能特点,广泛应用于谷歌内部产品及诸多开源项目,如PyTorch、Prometheus等。
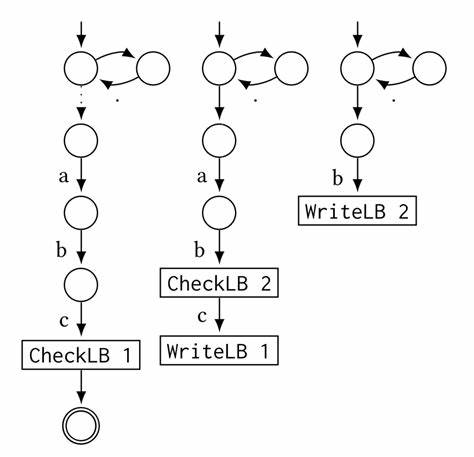
其底层核心结合了NFA(非确定性有限自动机)模拟、懒DFA(延迟确定性有限自动机)及位状态优化,确保常见正则表达式能以线性时间精准匹配。新增的捕获无关lookbehind扩展,主要依托于NFA引擎的架构改造实现。具体而言,算法设计思想基于在输入字符串扫描过程中,为每个lookbehind维护一个独立的位置记录表,实时更新lookbehind子表达式最后匹配的字符串位置。每个lookbehind子表达式被编译成独立的自动机,终止状态改写为写入当前字符串位置的操作(LBWrite),主自动机中则替换对应lookbehind为检查该记录表的指令(LBCheck)。执行时,将主自动机及所有嵌套lookbehind自动机并行锁步运行,优先执行更深层嵌套的lookbehind写入指令,保障匹配状态的同步与准确。RE2源码中,解析器部分新增了对捕获无关lookbehind语法模式的支持,扩展了语法树节点类型以识别正向和负向lookbehind,并在括号处理逻辑中建立专属节点。
编译器层面则引入了LBWrite、LBCheck两种独特指令及对应的编译逻辑,保证生成的自动机兼容整体结构。NFA执行引擎增加了专门的表结构存储lookbehind匹配位置,并根据当前扫描字符展开对应状态转移。当遇到LBWrite指令时更新位置信息,遇到LBCheck指令时判断当前字符位置是否满足lookbehind条件,确保正负向lookbehind的正确语义。为了不影响整体性能,RE2本次改动中将所有含lookbehind的正则表达式强制转入NFA模式执行,避免其他引擎因尚未支持此特性的潜在异常。测试方面,团队为解析器和引擎分别设计了覆盖完整语法节点及不同匹配场景的单元和集成测试,确保新增功能兼容原有功能且执行稳定可信。典型正向lookbehind如确认字符串中某子串前缀存在某模式,负向lookbehind则判断某子串前无特定模式。
性能测试显示,利用线性算法的RE2在含lookbehind的复杂文本匹配中保持逐字符线性增长的运行时间,远优于传统回溯式引擎的指数级衰减问题。RE2最新实现标志着正则表达式领域的一次重要飞跃,不仅使捕获无关lookbehind不再成为性能瓶颈,更为未来支持捕获相关lookbehind、lookahead及更复杂边界断言奠定了坚实基础。未来的研究方向还包括将线性匹配算法扩展至确定性自动机及多线程环境,以进一步提升大规模文本处理的效能和稳定性。此外,探索引入用户友好型调试与可视化工具也将帮助开发者更直观理解和优化使用复杂正则表达式。总的来说,RE2中引入线性时间捕获无关型lookbehind为正则表达式匹配技术注入了强劲动力,为基于正则的文本处理提供了更快速、更安全、可预测的解决方案。随着相关技术的深入推广和完善,相信未来正则表达式将在自然语言处理、网络安全、数据清洗等多领域展现更加卓越的应用价值。
。