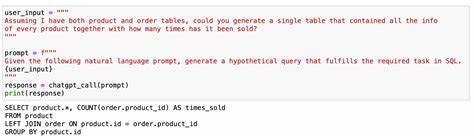
在当今的人工智能浪潮中,神经网络作为核心技术,深刻影响着自然语言处理、计算机视觉、机器人技术以及分子发现等多个领域。它们背后的共同点是基于可微分原语的构成,这种以函数为基础的方式被称为可微分编程。面向初学者的“可微分奇境历险记”引导我们踏入这个新奇且强大的世界,深入理解如何通过自动微分优化函数,掌握神经网络的设计与实现方法。 可微分编程的魅力在于其以数学“可微分性”为核心,通过链式法则对复杂函数进行求导,从而实现梯度计算,使得基于梯度的优化算法成为可能。自动微分技术尤其重要,它自动处理梯度计算,极大地简化了深度学习模型的训练过程。当前主流的深度学习框架如PyTorch和JAX,都充分利用了自动微分技术,使得开发者可以更加专注于模型设计而非繁琐的数学计算。
构建神经网络时,设计的关键是对不同类型数据目标的适应能力,比如时序数据、图结构数据、文本和音频信号。不同的网络模块如卷积层、注意力机制和循环神经网络块,分别擅长于不同的数据表现形式。卷积层有效提取空间或局部模式,广泛应用于图像和音频处理中。注意力机制革新了序列数据的处理方式,尤其在自然语言处理领域实现了突破,大幅提升了上下文理解能力。循环神经网络则适合处理时间序列数据,捕捉时间相关性和动态变化。在可微分奇境中,掌握这些模块的设计思想和实现细节,是理解复杂神经网络的基石。
随着研究的不断深入,深度学习模型也逐渐迈向多模态融合时代。大型语言模型(LLM)不仅在文本生成上表现惊艳,还结合图像、音频等多种输入,实现跨模态理解与生成。可微分编程为多模态模型的设计提供了灵活的框架,使得不同类型的数据流可以在同一个网络中协同优化。通过对可微分模块的组合和调试,研究人员和工程师不仅能够设计出功能强大的模型,也促进了人工智能在实际应用中的普及与创新。 “可微分奇境”核心讲述了桥梁作用——连接理论与代码之间的差距。对于广大机器学习学习者来说,不仅要理解数学原理,更应掌握如何用代码具体实现模型并调试优化。
这不仅涵盖了基础梯度下降法、损失函数设计等经典内容,还涉及最新的变种优化技术以及超参数调节方法。通过实战导向的学习路径,读者能够快速上手主流框架,理解代码背后的数学机理,进而灵活构建和改进自己的神经网络模型。 该教材还预示了未来人工智能研究的发展方向和挑战。随着模型规模和复杂度不断增加,如何设计高效、可扩展的可微分模块成为关键课题。同时,模型的可解释性、安全性和公平性也被提上日程,技术与伦理的结合成为不可回避的问题。可微分奇境引导读者认知这些现实问题,并探讨潜在的解决思路,例如通过创新的网络结构和训练范式,提升模型透明度与鲁棒性。
总而言之,探索可微分奇境不仅是理解深度学习技术的基础,更是掌握现代人工智能前沿技术的必经之路。通过学习自动微分、网络设计、多模态融合和优化策略,研究者和开发者可以站在技术的最前沿,推动工业和学术界的创新发展。在神经网络包围的世界里,每一次思考和实践,都是对未来智能社会的探索和铺垫。未来已来,唯有不断学习和应用,方能不被这场可微分奇境的奇妙旅程所迷失。