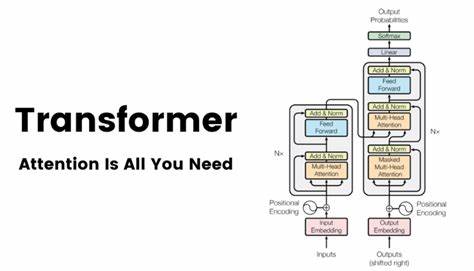
近年来,随着人工智能技术的飞速发展,深度学习模型在自然语言处理领域取得了令人瞩目的成果。其中,Transformer模型因其创新的架构设计和卓越的性能表现,成为深度学习研究的里程碑。Transformer彻底打破了传统基于循环神经网络和卷积神经网络的模型束缚,凭借纯粹的注意力机制,实现了高效且精准的序列转录任务。本文将深入解析Transformer的设计理念、工作机制及其在机器翻译等实际任务中的表现,揭示其为何被视为“注意力即一切”的典范。 传统的序列转录模型,如循环神经网络(RNN)及其变体长短期记忆网络(LSTM),虽然在语义理解与上下文联系方面表现良好,但由于其固有的顺序式计算特性,导致并行处理能力不足,训练时间长且难以捕捉长距离依赖关系。卷积神经网络(CNN)在一定程度上缓解了并行化的问题,但其感受野的限制使得处理序列信息时仍存在固有挑战。
与之不同的是,Transformer采用了一种全新的方法,完全依赖注意力机制而非循环或卷积运算,极大提升了并行计算效率,同时有效捕获长距离依赖。 Transformer模型的核心在于自注意力机制(Self-Attention)。该机制允许模型在处理序列的每个元素时,动态地关注输入序列中的其他所有元素,赋予模型对不同位置之间联系的灵活感知能力。具体来说,自注意力通过计算输入序列中所有元素之间的相似度得分,决定哪些信息对当前处理元素最为重要,从而集成相关上下文信息。这种全局依赖的捕获能力使得Transformer在理解复杂语言结构时表现出色。 除了自注意力外,Transformer还引入了多头注意力机制,将注意力计算并行拆分为多个“头”,每个头关注输入序列的不同子空间信息。
这样不仅丰富了信息表达,还增强了模型的表达能力和鲁棒性。此外,Transformer包含前馈神经网络层与层规范化(Layer Normalization),进一步提升模型的稳定性与训练效率。 Encoder-Decoder架构是Transformer实现序列转录的基础。编码器通过多层堆叠的自注意力和前馈网络,将输入序列映射为上下文丰富的隐含表示;解码器则结合编码器输出与自身生成的部分,使用掩蔽自注意力机制逐步生成目标序列,确保输出的依赖关系正确且有效。值得注意的是,Transformer通过位置编码(Positional Encoding)巧妙补充了序列的位置信息,弥补了不使用循环或卷积导致的顺序感知缺失。 Transformer在多个大型机器翻译基准测试中表现卓越。
以WMT 2014英德翻译任务为例,Transformer单模型取得了28.4的BLEU分数,显著超越此前最优结果。英法任务上,单模型更达到了41.8的BLEU分数,训练时间仅为传统模型的一小部分,充分展现了其高效性与优越性。此外,Transformer的结构优势使其易于扩展,适配不同规模与复杂度的任务,为NLP领域带来了极大灵活性。 Transformer不仅限于机器翻译,在诸如英语句法分析等结构预测任务上也表现优异。其强大的序列建模能力,使得模型能够适应从大规模数据训练到有限数据环境下的多样任务,展现出良好的泛化能力。随着后续变体的出现,如BERT、GPT等基于Transformer架构的预训练模型进一步推动了自然语言理解和生成技术的发展,Transformer的影响力不断深化。
此外,Transformer的设计理念正在逐步渗透到计算机视觉、语音识别和强化学习等领域,推动跨模态融合与多任务学习的新方向。研究者们持续探索优化注意力机制的计算效率和模型容量,以实现更大规模、更智能的AI系统。 总结来看,Transformer之所以成为最受瞩目的模型,源于其创新地用纯注意力机制代替传统循环和卷积结构,成功解决了序列处理中的效率及效果难题。其卓越的表现不仅在机器翻译领域树立新标杆,更催生了之后众多基于注意力的深度学习模型,推动了整个人工智能行业的技术革命。随着技术的不断创新,相信Transformer将在未来更多应用场景中发挥关键作用,驱动自然语言处理以及整个AI领域迈向新的高度。




![探讨[NE555]独特的表面贴装元件(SMD)原型制作方法,解析其在90年代日本兴起的精细手工电路板制作技艺,展现传统工艺与现代电子设计的完美结合。](/images/0B4BAFE0-0956-4B12-9F9C-0F4433284F50)