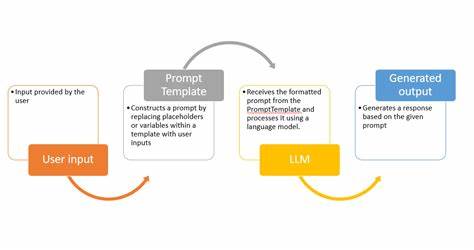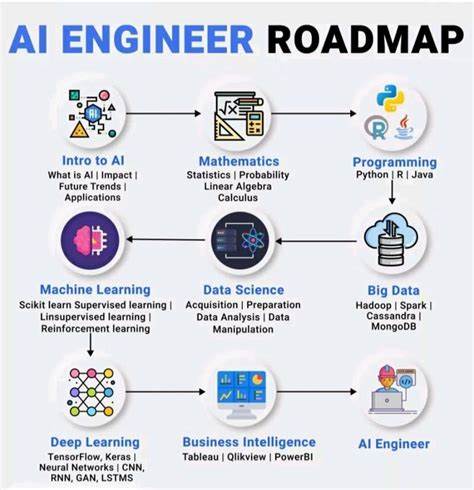
随着人工智能技术的快速发展,特别是大型语言模型(LLMs)的崛起,越来越多的技术爱好者和专业人士希望理解并深入学习这一领域。面对林林总总的学习资源与复杂的技术体系,一条清晰、有系统的学习路线图显得尤为关键。近年来,一份聚焦LLMs的现代AI学习路线图应运而生,为学习者搭建起一条明确有效的成长路径。 大型语言模型的学习首先应从其基本组件入手。这些核心模块包括分词(Tokenization)、向量嵌入(Embedding)、注意力机制(Attention)、前馈神经网络(FFN)、层归一化(LN)、残差连接(Residual Addition)以及位置编码(Positional Encoding)等。分词作为文本处理的基础,将语言转化为模型可理解的单元。
向量嵌入则是将分词转成数值向量,使模型能够捕捉单词之间的语义关系。注意力机制是LLMs的核心创新,帮助模型聚焦于重要信息,有效理解上下文关联。FFN负责对注意力输出进行进一步特征变换,层归一化与残差连接则保障模型训练过程的稳定性与高效性。位置编码赋予模型对于文本顺序的敏感度,使语言模型不仅“看”到内容,还能理解结构。 掌握这些组件后,学习者需进阶到LLM的预训练阶段。预训练是对模型进行大规模无监督学习的过程,目的是让模型在庞大的文本数据中提取通用的语言表示。
理解预训练定义及其数据来源,有助于明白模型持续成长的基础。同时,预训练流程包括数据预处理、模型训练调度以及混合精度训练策略,这些都是实现高效模型训练的关键。预训练结束后,模型需进行内部评估,确保基础能力达到预期,便于后续的针对性微调。 预训练只是大型语言模型发展的第一步,后期训练同样不可忽视。后期训练主要涵盖有监督微调(SFT)、强化学习以及从人类反馈中学习(RLHF)。有监督微调通过标注数据对模型进行定向训练,使其在特定任务上表现更佳。
强化学习及RLHF则通过奖励机制和人类评价引导模型优化输出,更好地满足用户需求和伦理要求。此外,诸如PPO算法优化和直接偏好优化(DPO)等现代方法,极大提升了训练效率和模型表现的精准度。 在了解训练机制的同时,熟悉业界主流的LLM模型同样重要。经典的BERT及其变体因其优异的双向编码能力深受欢迎。谷歌的PaLM系列在规模和多模态融合上表现突出。GPT系列作为生成式模型的代表,开创了语言生成的新纪元。
LLaMA、GLM、Qwen等新兴模型各有特色和技术突破,深刻影响着不同应用场景。更细分的诸如MoE网络架构和深度搜索系列则专注于提升模型效率与多任务适应能力。对这些模型的深入理解有助于学习者根据自己的目标选择合适的研究与应用方向。 理论离不开实践。结合实际应用,LLMs展现了巨大潜能。提示工程作为提升模型响应质量的重要手段,吸引大量关注。
基于LLM的智能代理逐步实现复杂任务自动化。检索增强生成(RAG)技术通过结合外部知识库,显著优化信息检索与文本生成的结合效果,广泛应用于企业级解决方案。对于初学者和开发者而言,实操项目如使用LangChain、nanoGPT从零训练GPT模型,以及对开源强化学习算法的深入剖析,提供了宝贵的实战经验和代码理解基础。 在性能优化层面,LLMs面临高计算需求和延迟挑战。探索GPU资源使用、推理延迟分析,以及诸如FlashAttention、PagedAttention等创新注意力机制,实现训练与推理的加速。同时,训练过程中的Packing技术和参数高效微调(PEFT)策略帮助降低资源消耗,提升模型的实用性与可扩展性。
在模型压缩方面,量化、剪枝与知识蒸馏等技术为部署落地铺平了道路,使得大型模型能够在资源受限环境下仍保持良好性能。 此外,掌握前沿必读论文和技术报告不可或缺。通过对背后的数学理论与算法创新有深入理解,学习者将能更好把握LLMs发展脉络,紧跟学术动态并应用于实际问题。近年来围绕归一化方法、激活函数、位置编码和解码策略的诸多技术突破,极大地丰富了模型设计和调优手段。 值得一提的是,开展系统化的LLM学习不仅能帮助个人提升技术能力,也对AI行业的发展起到推动作用。一个协调的学习生态与丰富的实战工程经验,将提升社区整体创新水平,催生更多基于LLM的智能应用,从而推动人工智能步入更广阔的应用领域与产业升级。
总之,构建一套全面且系统的现代AI学习路径对于任何想要涉猎大型语言模型领域的人来说有着重要意义。通过从基础理论到前沿技术、从模型架构到训练策略、从优化加速到实战应用的多维度掌握,学习者不仅能够消化海量技术信息,更能结合实际需求建构属于自己的知识体系。面对日新月异的AI技术,唯有持续系统学习与实践,方能在激烈竞争中立于不败之地,成就未来智能时代的弄潮儿。