随着互联网信息量呈爆炸式增长,如何在海量数据中高效地进行子串匹配搜索,成为了一个技术难题。尤其是在支持完整Unicode字符集的情况下,传统的搜索方法往往既耗时又容易丢失关键信息,满足不了现代网站对实时响应和精确搜索的需求。面对近千万级元素的网站,既要满足毫秒级响应,又要求不丢失任何Unicode字符,这考验着搜索技术的极限。近期,在一次实际项目中,开发者遇到了类似挑战。一位朋友运营的网站拥有约一千万条数据元素,每条数据包含丰富且复杂的文本内容,要求快速准确地找到包含目标子串的所有元素。不仅搜索响应时长要求极为严格,而且必须支持包括各种稀有字符和符号在内的完整Unicode字符集。
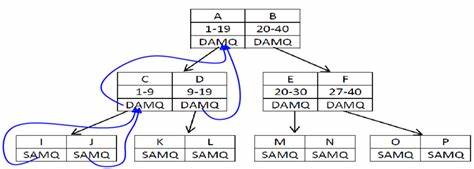
常规的字符串搜索方案无一不在性能或兼容性上掉链子,有些搜索响应时间昂贵,达到五百毫秒以上,严重影响用户体验;而有些方案虽然速度尚可,却往往针对Unicode支持不完整,导致搜索结果缺失。面对这一困境,工程师们开始重新评估和探索近似会员查询(Approximate Membership Query,简称AMQ)过滤器在该场景下的潜力。作为一种能够高效地判断一个元素是否属于某集合的数据结构,AMQ过滤器能够在保证零误报的同时,允许有限的误判,使得搜索过程得以大幅缩短。这种“可能属于”或“绝对不属于”的二元判断,为大规模数据过滤提供了理想方案。核心想法是将AMQ过滤器作为一种“门卫”,绝对排除不可能包含目标子串的数据元素,从而避免无效字符串的重复无谓扫描。针对这一需求,定制了一种基于字符位图的64位AMQ方案。
设计的灵感源自一个简单的事实:如果某个字符串包含一个特定的子串,那么该子串所含的所有字符必定存在于该字符串中。利用这个特点,将每个字符的Unicode编码取模得到在64位位图中的位置,通过设置对应的比特位来表示此字符串包含该字符。这种位图既轻巧又高效,极大节省了存储成本,非常适合亿级数据场景。在搜索时,同样为查询子串生成相应的64位位图指纹。对数据集中的每个元素,执行快速的位与操作,将元素位图与查询位图进行比对,如果元素位图中完全包含查询位图,这意味着该元素字符串拥有查询所需的全部字符,需进一步执行真正的字符串查找以确认匹配。否则,该元素字符串必定不包含目标子串,可立即跳过,实现高效的预筛选。
这种方法巧妙利用了位运算的优势,极大缩减了传统字符串子串搜索必须逐一比对的大量开销,将复杂度降低到近乎常数的运算代价,性能提升非常显著。从实际应用结果来看,搜索速度由原本几百毫秒级别缩减至低于十毫秒,直接提升数十倍响应效率。该方案有效过滤了绝大多数不匹配的字符串,真正进入全字符串匹配阶段的仅为极少数,显著节省了系统资源。此外,整个流程天然支持所有Unicode字符,无需特殊处理,避免了字符集兼容性漏洞,为全球多语言应用场景提供了完美的解决方案。该定制AMQ过滤器的核心优势首先体现在简约高效的数据表示上。利用64位位图截取字符特征,在存储和计算方面达到了极致优化。
其次,其查询流程简单而直观,任何编程语言均可快速实现,易于集成与维护。再者,设计上保证了零误判的“否定”答案,即当返回“不包含”时,绝对可信,大幅提升搜索结果的准确性和信赖度。最后,该技术开源AGPLv3许可发布,利于社区共建和迭代创新,适合各种规模数据系统采纳。当前,面对海量信息爆炸,任何能够降低搜索延迟同时支持多语言兼容的解决方案,都将极大推动在线内容管理与信息检索领域的发展与进步。定制AMQ过滤器以其独特的设计理念,为传统字符串子串搜索领域注入了新的活力和思路,成为了处理复杂Unicode文本搜索的理想方法。未来,该方法还可进一步结合现代硬件特性、高并发系统架构及机器学习技术,提升搜索系统的智能化和自动适应能力,推动大数据检索迈向更高效和精确的新时代。
通过创新设计与工程实践的紧密结合,AMQ过滤器证明了算法优化和数据结构创新在解决实际应用瓶颈中的巨大价值,开启了智能信息检索的新篇章。