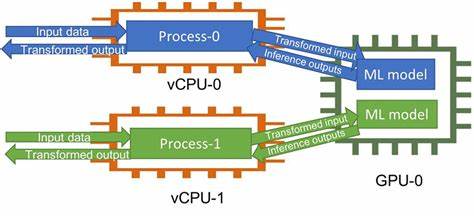
随着人工智能技术的迅猛发展,深度学习模型的规模和复杂度不断攀升,推动了对计算硬件性能和显存容量的极高需求。尤其是在推理环节,多任务并行运行和多个独立进程同时调用模型已成为提升系统吞吐量和响应速度的重要手段。但随之而来的问题是,每个进程单独加载模型会占用巨量宝贵的GPU显存资源,导致显存瓶颈严重影响整体系统效能。近年来,一种创新的显存共享技术逐渐成为业界关注的焦点,通过在多个独立推理堆栈进程间共享基础模型,来实现显存的最大化利用和成本优化。本文将围绕该技术的原理、实现方案和实际应用展开深入阐述,助您了解GPU显存共享的前沿动态及其对AI生态的深远影响。传统GPU推理场景中,每一个推理进程往往需要将基础模型(如大规模预训练变换器模型)完整加载至自身的显存空间。
这种"重复占用"导致GPU显存资源迅速被消耗殆尽,限制了能够同时并行运行的推理任务数量,带来高昂的硬件投入成本。针对这一问题,GPU显存共享机制应运而生,其核心理念便是将模型的权重及中间数据在不同推理堆栈进程间复用,通过显存去重(deduplication)技术确保基础模型只占用一份显存空间,而每个推理进程则拥有独立的适配层或状态。实现显存共享的关键技术障碍主要包括如何构建跨进程可访问的显存映射,确保数据访问的一致性和安全隔离,以及在不同推理框架间的兼容性问题。以WoolyAI GPU Hypervisor为例,它通过引入底层GPU虚拟化层和显存管理层,实现了多进程间对同一基础模型权重的显存共享。该方案有效解决了传统单机多进程模型加载的显存冗余问题,支持在单块GPU上部署多个独立的LoRA适配器堆栈,极大提升了显存利用率及并行推理容量。通过显存复用机制,一个GPU可同时支撑更多的推理服务,实现更高的计算效率和成本效益,特别适用于需要快速部署多样化模型适配方案的企业级AI应用场景。
该技术不仅降低了GPU硬件投资门槛,也减少了能耗和系统运维复杂度,真正实现了绿色高效的AI推理基础架构。从技术实施层面来看,实现显存共享还需结合底层驱动开发和GPU内存管理策略的优化。显存去重机制通常依赖于对相似数据的指针共享和写时复制(Copy-On-Write)技术,保证不同进程在共享数据时具备必要的隔离性和数据完整性。此外,合理调度推理请求和管理显存访问权限,也是提高整体系统稳定性和吞吐量的关键。除了GPU和推理框架本身,需要配套完善的监控与调度工具,帮助开发者实时掌握GPU显存使用情况,及时发现潜在冲突与瓶颈,确保多进程模型推理环境的高效运行。值得关注的是,GPU显存共享技术对AI模型开发流程也提出了新挑战。
适配共享机制的模型设计需要考虑权重非侵入式调整,保证基础模型权重只读,避免多个堆栈进程相互影响。同时,LoRA等参数高效调整方法成为实现轻量适配的理想方案,使得共享基础模型与个性化适配配置兼容。未来,随着GPU硬件虚拟化能力的不断提升,及更完善的软件生态支持,显存共享技术将成为推动多模型、多任务多进程推理平台发展的核心动力。它不仅有望缓解目前AI推理部署面临的硬件和成本瓶颈,也将催生更多创新应用,使得AI技术更容易规模化、模块化落地。总之,基于GPU显存共享的多推理堆栈基础模型复用方案,是深度学习推理领域的一项重大技术进步。它突破了传统显存资源的限制,提供了更灵活、高效的GPU利用途径,成为面向未来AI算力架构的关键创新。
无论是AI服务提供商,还是科研机构与企业研发团队,都应高度关注和积极实践该技术,为打造可持续、低成本、高性能的智能推理平台奠定坚实基础。 。