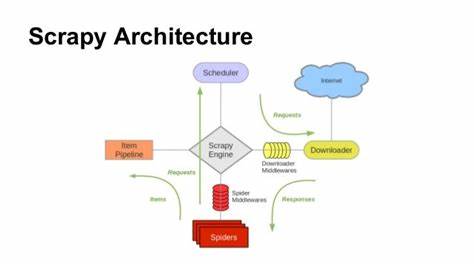
在当今互联网信息爆炸的时代,网络爬虫作为数据采集的核心工具,扮演着越来越重要的角色。面对海量数据与日益复杂的网站结构,开发高效且稳定的爬虫框架变得至关重要。Scrapy_cffi作为一种创新性的异步优先爬虫工具,正逐步吸引业界关注,以其灵活、高性能和模块化设计,为开发者带来了全新体验。 Scrapy_cffi的设计理念融合了传统Scrapy框架的架构优点,同时舍弃了传统依赖的Twisted事件循环,转而采用了现代高性能的curl_cffi作为底层HTTP与WebSocket客户端。这一变革有效提升了爬虫的并发能力和响应速度,令异步处理真正做到极致,适合大规模分布式爬虫部署。 作为一款轻量级的Python爬虫框架,Scrapy_cffi保持了Scrapy中广为人知的蜘蛛(Spider)、项目项(Item)、中间件和管道(Pipeline)、信号(Signal)等模块化组件,降低了上手门槛。
同时,Scrapy_cffi的异步引擎使得爬虫能够高效处理大量HTTP请求和实时数据流,尤其在面对需要同时维护大量连接的WebSocket协议时,表现尤为出色。 Scrapy_cffi不仅支持HTTP协议的常规爬取,还原生支持WebSocket,满足了现代网页实时通信需求。借助curl_cffi的支持,实现对TLS安全连接的稳健管理,大幅提升爬取任务的安全性与稳定性。此外,框架本身内置了灵活的数据库集成功能,涵盖Redis、MySQL和MongoDB等主流存储系统,支持异步重试与自动重连机制,保障数据处理过程不中断,进一步提升系统的鲁棒性。 消息队列系统的集成是Scrapy_cffi在大规模分布式爬取场景中的另一大优势。内置对RabbitMQ和Kafka的支持,使得任务调度和结果处理流程更加高效灵活。
通过配置文件,用户可以轻松切换单节点、集群模式或者Redissentinel模式,实现任务的高可用分发和容错能力,使爬虫系统更具扩展性和可靠性。 Scrapy_cffi还创新性地引入了轻量级的拦截器和中间件系统,方便开发者根据需要灵活定制请求的处理流程和响应解析逻辑。这种设计极大地增强了框架的可扩展性,使得无论是简单的单机爬取任务,还是复杂的分布式数据采集,都能以最合适的策略完成。 在性能优化方面,Scrapy_cffi引入了基于C语言的扩展钩子,用于处理CPU密集型任务。这意味着爬虫框架能够直接调用本地高效代码,显著提升计算性能,减轻Python层的负担,有助于更好地应对大并发及复杂数据解析需求。 部署与配置方面,Scrapy_cffi设计了灵活的设置系统,支持从Python脚本和.env文件中加载配置。
这个系统方便用户集中管理数据库连接参数、消息队列设定和并发限制等核心参数,简化了爬虫的运维流程。针对分布式环境,Scrapy_cffi还能通过配置Redis哨兵模式,增强数据存储的可靠性和容错能力,确保长期稳定运行。 Scrapy_cffi提供了标准的命令行工具,方便用户快速创建项目和蜘蛛模板,极大加快了爬虫开发速度。值得注意的是,从不同版本开始,命令行工具名称略有变化,用户应根据所用版本选择使用scrapy_cffi还是scrapy-cffi命令。 在任务调度策略方面,Scrapy_cffi针对Redis和RabbitMQ调度器进行了细致改进,避免了队列清空时自动终止的问题。开发者可以根据自身需求设置调度器循环次数,实现对长时间监听的持久性蜘蛛的支持,提升整体任务连续性和稳定性。
Scrapy_cffi的发展背景源于人们对异步Python爬虫的实际需求。它有效解决了传统同步爬虫面对的请求阻塞、数据库操作缓慢及复杂分布式环境下的协调难题。通过采用curl_cffi异步库,结合模块化设计,Scrapy_cffi实现了真正意义上的全异步爬取流程,确保了爬虫任务的高效率与高并发处理能力。 此外,Scrapy_cffi的开源性质意味着开发者可以自由定制与扩展,同时也得益于社区贡献,不断完善和优化。该项目目前托管在GitHub上,采用BSD 3-Clause开源许可证,保证了软件的自由使用与传播。 总结来看,Scrapy_cffi是一个专为现代爬虫需求打造的异步优先框架,凭借其高并发的curl_cffi底层支持、多协议协同处理、灵活的分布式部署方案以及模块化的设计理念,成为构建高效稳定爬虫系统的理想选择。
无论是个人开发者还是企业级用户,都能通过它快速构建适应多变网络环境的强大采集工具,助力大数据时代的信息获取与利用。 未来,随着Python异步生态的不断成熟与完善,Scrapy_cffi有望持续优化底层性能,增强多协议兼容性,进一步提升扩展性和易用性,成为爬虫领域的领先开源项目之一。对于追求高效爬取和大规模数据处理的开发者来说,深入学习和掌握Scrapy_cffi,无疑是迈向现代爬虫技术前沿的重要一步。 。