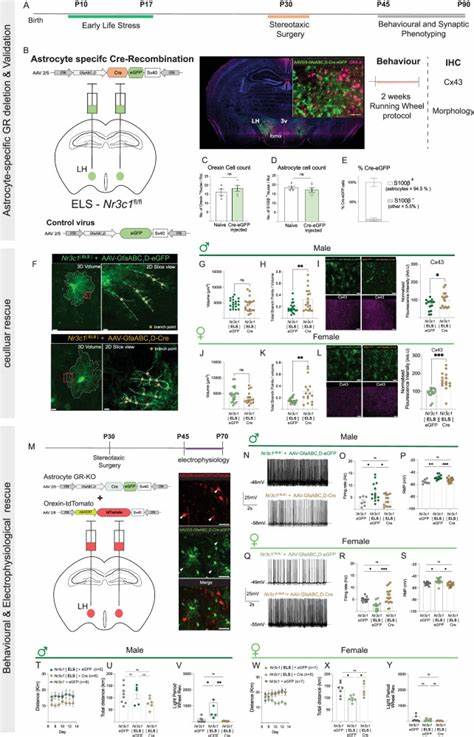
近年来,人工智能在医疗健康领域的应用日益广泛,特别是大语言模型(LLM)的崛起,为医疗问答、决策支持和临床辅助诊断提供了极大便利。然而,尽管如ChatGPT、GPT-4等通用大语言模型在理解自然语言与生成流畅文本方面表现优异,直接将其应用于临床医疗药物分析却面临诸多挑战。其中,幻觉生成(即模型输出看似合理却不真实的错误信息)和缺乏证据溯源成为阻碍其广泛应用的关键瓶颈。针对这些难题,DrugGPT作为一款创新的协作式大语言模型诞生,利用多样化的临床标准知识库实现了安全、精准且具备可追溯性的药物分析服务。DrugGPT基于三个核心互助模块构建:询问分析LLM(IA-LLM)、知识获取LLM(KA-LLM)以及证据生成LLM(EG-LLM)。这些模块协同作用,实现了从理解疾病及症状、精准检索知识库内容,到生成基于实证的回答的全过程闭环。
Inquiry Analysis LLM通过先进的链式思维(Chain-of-Thought)及少样本学习提示微调等技术,提升对医疗询问的理解和拆解能力,为后续的知识检索环节提供清晰指引。Knowledge Acquisition LLM负责从包括Drugs.com、英国国家医疗服务体系(NHS)以及PubMed在内的权威临床数据库中,检索并提取相关的药物及疾病知识。其利用构建的疾病-症状-药物知识图谱(DSDG)对实体间关联建模,提高知识检索的全面性与精确性。Evidence Generation LLM则基于提取出的可信知识,通过知识一致性提示(Knowledge-Consistency Prompting)和证据可溯提示(Evidence-Traceable Prompting)策略,生成符合医学事实且附带来源信息的回答。这种设计不仅极大降低幻觉生成的风险,也保障临床用户能实时追踪答案背后的数据出处,增强模型输出的透明度和专业可信度。该系统特点在于灵活使用多样的知识来源,并通过协作机制有机整合各模型优势,使药物推荐、剂量建议、不良反应识别及药物相互作用分析等任务均达到或超过当前业界最高水平。
在11个覆盖药物推荐、药理学问答、药物不良反应(ADE)及药物相互作用(DDI)等多个维度的公开数据集测试中,DrugGPT均优于Anthropic Claude-3、GPT-4及ChatGPT等知名大语言模型。尤其在专业医学认证考试如美国医师执照考试(USMLE)的相关题目中,DrugGPT表现出超越人类专家的答题准确率,凭借对事实和证据的严格控制,有效避免了传统模型容易出现的误导性回答。此外,在新药识别和跨领域泛化能力方面,DrugGPT同样展现出强大的适应性。通过专门构建的DrugBank-QA和COVID-Moderna数据集,系统不仅验证了其对最新上市药物的处理能力,也展示了面对药物类别、作用机制及类型多样性的普适适应性。与普通大语言模型相比,DrugGPT在这些尚未被广泛纳入训练集的药物信息上依然能给出高准确率的建议,证明了其知识更新机制和知识图谱驱动检索的有效性。人类专家评价环节中,两位医学领域权威分别基于准确性、完整性、安全性及用户偏好等多项指标对模型输出进行盲测。
评审结果明显支持DrugGPT的临床实用价值,特别是在生成具备证据溯源能力的内容上获得远超ChatGPT和GPT-4的高分,进一步奠定了其在医疗诊断辅助工具中的领先地位。同时,系统针对知识库规模的扩展性表现出极高的鲁棒性。从知识使用量为1%逐步提升到100%的实验证明,DrugGPT性能持续稳步提高,即使在知识资源有限的场景下亦可达到与当前顶尖模型相媲美的效果。这为其未来向其他医疗领域如疾病诊断、预后分析等的迁移应用提供了坚实基础。技术实现层面,DrugGPT采用了大量前沿的提示工程与图神经网络技术。知识图谱通过基于语义嵌入的节点相似度计算构建,实现了疾病、症状与药物间的关系精准映射。
提示调优阶段则利用固定模型参数基础上微调软提示策略(Soft Prompt Tuning),显著降低训练成本和计算资源需求。EG-LLM结合多种提示策略,模拟人类专家推理逻辑,保障输出推理过程和结论的连贯及可信。值得一提的是,DrugGPT不仅仅是面向药物领域的问答模型,其设计理念和架构充分体现了让大语言模型结合可验证知识库,通过协作式推理有效规避幻觉风险和增强证据透明性的全新范式。这一范式极有可能引领未来医疗AI系统的发展方向。业界期待它能够进一步嫁接更多临床数据和实时更新机制,推动AI临床辅助诊疗向更广泛、更智能化应用演进。总之,DrugGPT凭借其知识驱动的协作机制、严格的证据溯源和卓越的临床推理能力,为当前大语言模型在医疗药物分析领域的应用带来了突破。
它解决了通用模型幻觉频发和缺乏可靠依据的问题,提供了面向临床决策的安全与高效解决方案。未来,随着技术迭代与知识库扩充,这样的专业协作大语言模型将逐渐成为医生、药剂师及医疗机构进行精准用药、个体化治疗的得力助手,推动智能医疗新纪元的到来。 。