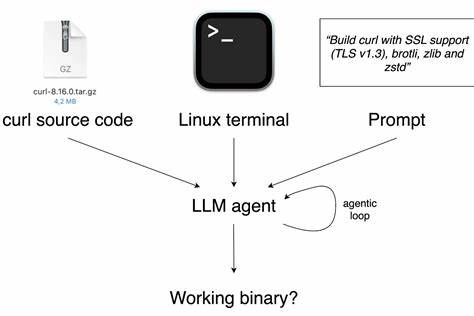
随着人工智能技术的迅猛发展,越来越多的领域开始依赖于人工智能辅助完成复杂的任务。在软件开发领域,尤其是在处理旧代码和复杂构建流程时,人工智能展现出了显著的潜力。近来,一项名为CompileBench的基准测试引起了广泛关注,它专注于评估不同大型语言模型(LLM)在编译老旧代码方面的能力,特别是针对多达22年前的软件项目。本文将深入探讨CompileBench的内容、测试结果、基准设计思路以及人工智能如何帮助我们攻克传统技术难题,为未来的软件维护和二次开发带来新的可能。CompileBench由Piotr Grabowski和Piotr Migdał联合推出,是当前业界少见的专注于编译能力的AI性能评测。评测不仅涵盖了标准的本地编译,还涉及到交叉编译(例如将gucr软件编译为ARM64架构),这对模型的综合能力提出了非常高的要求。
通过模拟复杂的构建环境和繁琐的依赖关系,CompileBench旨在逼真地还原过去软件开发环境中的现实难题,从而检验AI在此类场景的实用性和鲁棒性。值得注意的是,CompileBench采用的是最小化的基准框架和通用提示(prompt),未针对特定模型进行过度调整或优化,保证了测试的公平性和客观性。该基准采用的交互工具主要是单一的run_terminal_cmd命令工具,模拟在Ubuntu 22.04 bash环境下自动化执行shell命令,评估模型通过一系列非交互式指令成功完成编译任务的能力。测试中对模型的容错能力和自我修正机制亦有严格要求,模型在遇到错误时需自主解决并确保最终输出符合预期。贯穿整个测试的系统提示(system prompt)设定了包构建专家的身份,并明确执行规则包括使用非交互式标志、避免换行符、允许sudo权限等细节,确保模型操作符合真实开发环境下的最佳实践。最近的评测结果显示,Claude Opus 4.1 Thinking在三次尝试限制内率先实现了100%的问题解决率,成为本次基准的领跑者。
紧随其后的是Claude Sonnet 4 Thinking和GPT-5 high,均取得了93%的优异成绩。值得一提的是,在开源权重模型中,DeepSeek 3.1和Kimi K2 0905都表现不俗,达到80%的正确率,显示出开源模型在特定任务上也已具备较强竞争力。另一方面,Gemini 2.5系列模型表现令人意外,仅解决了60%的问题。基准设计者指出,尽管当前未针对谷歌模型进行特定的提示优化,但有理由相信经过定制化调优后,谷歌系模型可能展现更好效果。不过,为了保持评测的统一和可比性,此基准坚守最小化调优原则,避免引入模型特征偏差。关于成本效益方面,测试结果表明,GPT-5-mini在综合性能与使用成本之间保持了极佳的平衡,为用户提供了极高的价值。
CompileBench的代码开源在GitHub上,主要使用Go语言编写。核心代理循环逻辑位于bench/agent.go文件内,并基于OpenAI Go库进行构建。用户和开发者可轻松检查和复现基准过程,促使社区共同推动AI在编译领域的进步。折射到实际应用层面,像Claude Code和Codex CLI这样的智能编码代理工具,极大地降低了程序员面对遗留系统和复杂构建脚本时的心理阻力。曾经棘手的依赖解决、配置调优以及多架构交叉编译流程,如今都可以借助智能模型进行自动尝试和错误修正,大幅提升软件维护效率和代码复用价值。由此可见,CompileBench不仅是一个评测工具,更是推动人工智能编码辅助技术迈向新阶段的重要里程碑。
它揭示了AI在传统编译任务中的应用潜力,也反映了未来自动化软件构建和维护的方向。面对工业界日益增长的技术债务和遗留代码维护需求,能够依靠AI对过去的代码进行有效解析和重建,将成为企业持续创新的关键。而从更广义的角度看,CompileBench的成功也验证了大规模语言模型在理解和执行高度结构化任务上的能力,将促进AI技术更深入地融入软件工程工作流。如何进一步提升模型在复杂环境下的适应性和问题解决能力,利用多模态信息丰富语境理解,构建更为鲁棒的自动化构建体系,是未来研究和工程应用的重要方向。总结而言,CompileBench对AI编译22年前代码的探测不仅展示了当前技术的成就,也映射出未来软件智能化发展的广阔前景。随着模型性能持续提升及编译环境模拟更加真实,我们或许很快能看到AI成为软件维护者的"得力助手",彻底改变传统编码和构建的格局。
对于软件开发者、技术管理者及AI研究者而言,关注并参与这样的前沿项目,将有助于把握行业趋势,推动智能编程工具的创新与普及。 。