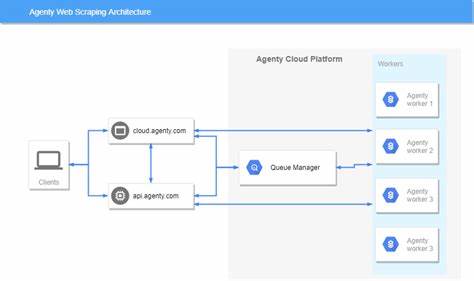
随着互联网信息的爆炸式增长,网页数据采集技术的重要性日益凸显。AnyCrawl作为一款高性能爬虫和网页抓取工具,以其多线程处理能力和灵活的API接口,成为开发者以及企业的数据采集利器。最新发布的v0.0.1-alpha.5版本更进一步优化了功能,支持自定义用户代理,并提供了更加丰富的抓取API接口,为复杂的爬取任务带来更强大的支持。AnyCrawl的设计初衷是为AI生态系统打造简单、可靠且可扩展的抓取解决方案,帮助用户轻松实现结构化数据的提取和大规模信息的收集。该工具不仅支持传统的静态HTML解析,还内置了基于Playwright和Puppeteer的现代浏览器渲染引擎,方便应对JavaScript动态生成内容的网页抓取。此版本中,开发团队重点增强了API的灵活性和可用性,用户可以精准配置爬取参数,比如指定代理服务器,控制爬取深度及范围,同时实现对网站路径的细粒度筛选。
自定义用户代理的功能设计,帮助爬虫模拟不同类型的访客请求,提升访问成功率并规避反爬虫机制,有效保障数据采集的连续性和稳定性。AnyCrawl不仅专注于基础抓取,还深度整合了大语言模型(LLM)技术,能够直接从网页内容中提取结构化JSON数据,极大提升了数据清洗和处理效率。通过简单的schema定义,用户即可让系统智能识别并抽取公司信息、产品特征、文章重点等多样内容,拓宽了爬虫的应用边界,例如商业情报分析、市场调研及内容聚合等。该工具的高性能多线程设计,使得批量任务能够并行执行,有效缩短总耗时,适合大规模网站全站爬取以及多引擎搜索结果聚合。对于搜索引擎结果页面(SERP)采集,AnyCrawl支持Google等主流引擎,围绕关键词实现多页结果批量抓取,并支持语言和区域过滤,大幅提高搜索分析的精准度。任意复杂爬虫配置通过JSON格式参数传递,使得API调用简单直观,方便二次开发和功能扩展。
AnyCrawl提供稳定的代理支持,内置高质量默认代理服务,也允许用户接入自定义HTTP或SOCKS代理,进一步强化访问灵活性和匿名性,适应不同网络环境和安全需求。这些特性使AnyCrawl不仅适合有技术背景的开发者使用,也方便中小企业和数据科学家快速集成网络数据,提高工作效率。同时AnyCrawl的开源属性及完善的文档,促成社区活跃合作,持续推动功能进步和用户体验优化。作为一款基于Node.js和TypeScript的现代爬虫框架,AnyCrawl代码层面注重模块化和可维护性,支持Docker镜像部署以及多架构构建,保证在不同操作系统和云平台环境中顺畅运行。团队还重视API的安全机制,内建认证和信用额度管理,保障服务稳定且防止滥用。通过官方网站和在线Playground,用户能够方便地测试API功能,生成多语言代码示例,降低上手门槛。
任何希望采集网络数据、实现智能分析的用户,都能从AnyCrawl丰富的功能集中获得显著价值。总结来看,AnyCrawl v0.0.1-alpha.5借助自定义用户代理、多线程爬取、AI结构化提取等前沿技术,提供了易用且强大的工具链,适配多样化采集场景,推动网络数据利用进入新阶段。未来,随着版本迭代和社区贡献,AnyCrawl有望持续优化性能和扩展能力,助力更多行业实现精准数据驱动决策。无论是学术研究、市场调研还是内容聚合,AnyCrawl都以其开放、高效和智能的特性成为网络爬虫领域的重要选择。