随着大数据和人工智能技术的不断发展,实时流处理成为数据分析与应用的关键方向。流数据的高速、多样性以及实时性要求开发者拥有高效、可靠且灵活的解决方案。StreamPark正是在这样的背景下应运而生,作为一个开源的流应用开发框架和云原生实时计算平台,StreamPark为开发者提供了便捷的开发、调试、部署和运营体验,极大地提升了流处理应用的整体效率和管理水平。 StreamPark最初名为StreamX,于2022年8月更名为StreamPark,并在2025年1月晋升为Apache顶级项目。这标志着其在开源社区的认可以及技术成熟度的提升。作为一款全面支持Apache Flink和Apache Spark的统一流处理开发框架,StreamPark将批处理和流处理进行了融合,满足了多样化的数据处理需求,帮助企业快速构建高性能的实时数据应用。
StreamPark的核心价值体现在多个方面。首先,它通过丰富的API、连接器和模板极大简化了Flink和Spark的流处理开发流程。开发者无需从零开始编写复杂代码,而是能够通过StreamPark预设的组件快速搭建应用架构,缩短研发周期,提高开发效率,同时减少出错风险。其次,StreamPark具备强大的云原生属性,支持多种运行环境,包括Standalone、Hadoop YARN(2.x/3.x)以及Kubernetes,让用户能够灵活选择和切换部署方式,充分利用云计算资源,提高系统弹性和可扩展性。 在多版本和多引擎支持方面,StreamPark允许用户同时运行和管理多个版本的Flink和Spark应用。企业可以基于不同业务需求或版本特性,灵活切换和升级流处理程序,避免开发与运维的复杂度提升。
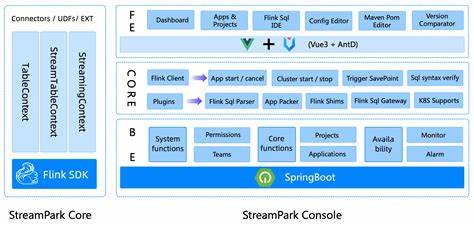
此外,StreamPark与主流大数据生态系统高度兼容,支持Apache Paimon、Doris等知名组件,亦可集成机器学习和人工智能工具,形成完整的数据处理和分析生态链,满足智能化数据应用需求。 StreamPark强调用户体验的简易性,仅需单服务部署,用户即可迅速开始开发,几分钟内完成首次任务运行。这对于数据团队和开发者来说极具吸引力,消除了传统流处理框架复杂配置的门槛,使得各类企业和组织能够以较低成本探索和实践流处理技术,快速获得业务洞察。 从技术架构的角度来看,StreamPark采用模块化设计,包含流处理核心模块、控制台管理界面、测试用例及多语言支持等多项功能模块。控制台提供了便捷的任务监控、日志管理和报警机制,确保流处理任务的稳定运行。开发者可以通过Web UI直观管理应用生命周期,实时查看任务状态和指标数据,提升运维效率。
StreamPark的应用领域广泛,涵盖金融、互联网、电商、物联网、智能制造等多个行业。在金融领域,StreamPark可用于实时风险监控、异常检测及交易分析,助力金融机构显著提升风控能力和交易效率。在互联网和电商领域,实时用户行为分析、推荐系统和广告投放优化均可借助StreamPark实现更精准的实时计算和响应,提高用户体验和业务转化率。智能制造则借助StreamPark实现设备状态监控、故障预警,推动工业互联网建设。 从生态建设的角度,StreamPark积极推动开源社区的发展,拥有160多名贡献者,代码库涵盖Java、Scala、TypeScript、Vue等多种主流编程语言,显示出项目的活跃度和技术多样性。开发者通过提交PR和Issues积极参与项目建设,使得StreamPark不断完善功能和增强稳定性。
社区还提供详尽的文档、快速入门指南和视频教程,降低新用户的学习成本,同时保持项目的创新活力。 StreamPark在帮助企业实现数据价值的过程中,也体现出大势所趋的多引擎、多云、多环境融合发展趋势。它不仅提升了企业的技术自主权,还有效节约了运维成本和开发难度。通过StreamPark,企业能够实现从数据采集、处理到应用的全流程自动化,实现业务的实时智能化升级。 总而言之,作为一个集开发框架和云原生实时计算平台于一体的平台,StreamPark凭借其易用性、兼容性和高性能优势,极大地推动了流处理技术的普及和应用。对于希望在大数据时代抢占先机的企业和开发者来说,掌握并利用StreamPark无疑是迈向数字化智能转型的重要一步。
未来,随着流处理技术和云计算的发展,StreamPark也必将在更多复杂业务场景中展现其强大价值,成为流数据时代不可或缺的核心利器。