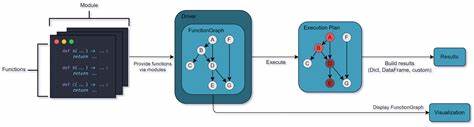
在当今数据驱动的时代,企业和组织面临着源源不断的数据挑战,如何高效地进行数据转换、处理和管理成为实现业务价值的关键。Apache Hamilton作为一款开源且轻量级的Python库,为数据转换过程中的有向无环图(DAG)构建提供了创新的解决方案,极大地简化了数据转换的复杂度,提高了代码的可维护性和执行效率。 Apache Hamilton的设计初衷是为了让数据科学家和数据工程师可以像编写普通Python函数一样定义数据转换逻辑,系统自动解析这些函数之间的依赖关系,形成高效且结构化的数据转换DAG。这种方式不仅确保了代码的清晰易读,还使得开发者能够专注于业务逻辑本身,无需为繁琐的依赖管理和流程调度而分心。 相比于传统的DAG构建工具,Apache Hamilton具备高度的可移植性。无论是在交互式的Jupyter笔记本环境中,还是在生产级的Airflow管道、FastAPI服务,甚至是独立的Python脚本内,都能无缝运行。
如此灵活的设计使团队能够在不同环境中共享和复用转换逻辑,提高开发效率并降低运维难度。 除了基本的DAG构建能力,Apache Hamilton还提供了丰富的扩展功能来满足现代数据工程的多样需求。例如,通过函数修饰器和配置管理功能,开发者可以根据不同的执行环境动态修改DAG行为,从而避免了大量冗余代码和错误易发的条件判断。这种高表达性的设计极大地提升了代码的可维护性和复用性,使大型和复杂的数据转换工作流的管理变得更加高效和可控。 数据质量和一致性是数据转换过程中的重要保障。Apache Hamilton内置了数据验证机制,允许开发者通过装饰函数的方式为每个转换步骤定义输出校验规则。
借助SchemaValidator等适配器,能够自动检查诸如Pandas、Polars等数据框架中的数据模式,及时捕获异常和潜在问题,为数据质量提供坚实保障。这种设计也方便团队进行单元测试和自动化验证,显著降低数据错误带来的风险。 在数据平台或机器学习管道的开发过程中,协作常常是巨大挑战。Apache Hamilton的UI界面专为团队协同设计,它不仅可以自动生成数据转换DAG的可视化图谱,还能实时追踪执行情况和结果。团队成员借助这一共享平台,能够方便地检查数据血缘、调试失败任务,并进行成果的快速复现和分析。通过项目和用户管理功能,整个开发周期的监控与管理变得高效且透明。
其背后的技术架构设计也极具前瞻性。Apache Hamilton支持将多个Python模块组合成复杂的数据流水线,鼓励模块化编程风格。在大规模项目中,团队可以将不同业务域的转换逻辑拆分成独立模块,结合构建单一DAG,实现松耦合、高内聚的代码体系。这种结构既符合软件工程的最佳实践,又满足现代数据工作的需求。 更值得关注的是,Apache Hamilton不仅专注于DAG的构建,也为与其他生态系统的集成提供了良好支持。无论是嵌入现有的数据仓库体系,还是结合成熟的机器学习平台,甚至支持远程执行和实验追踪,Hamilton都能灵活适配,通过插件机制开放对自定义工具链的支持。
活跃的社区为用户提供持续的技术支持和创新扩展,确保项目的稳定发展与快速演进。 从诸多实际案例来看,Apache Hamilton已广泛应用于不同行业的生产环境。例如,全球领先的电商平台Stitch Fix利用Hamilton开展时序预测与特征工程;英国政府数字服务部门借助其实现国家级反馈数据管道处理;IBM、Adobe等大型企业也在内部搜索、ML管道和复杂特征计算中引入该工具,展示了其强大的实用价值和适用范围。 对于初学者,Apache Hamilton同样友好。通过直观的Python函数接口、完善的文档和丰富的示例代码,用户可以快速上手并深度掌握其核心理念。官方还提供了丰富的学习资源,包括视频教程、社区讨论和博客文章,帮助用户应对各种场景与挑战。
此外,自己托管的UI界面也方便团队开展项目管理和协作。 总结来看,Apache Hamilton是一款将软件工程最佳实践引入数据转换领域的创新工具。它通过基于Python的声明性函数定义,自动管理复杂的数据依赖关系,提供可视化和数据验证功能,支持多环境多场景的灵活执行,助力数据团队提升数据质量,提高开发效率,降低协作壁垒。对于渴望打造模块化、易维护且可扩展数据工作流的企业和开发者而言,Apache Hamilton无疑是一个值得深入探索的重要选择。随着数据规模和复杂度不断增长,借助像Hamilton这样的工具提升治理能力和运营效率,将成为现代数据架构的关键驱动力。未来,随着社区的不断发展和特性迭代,Apache Hamilton有望在数据转换和数据工程领域发挥更加核心的作用,帮助更多组织实现数据价值的最大化。
。