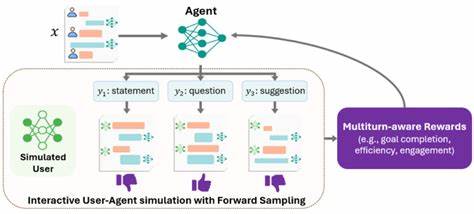
随着人工智能技术的迅猛发展,AI系统已广泛应用于医疗、金融、交通、制造等多个领域。然而,如何确保这些系统的安全性、可靠性和高效性成为业界关注的核心问题。人工智能的测试与评估作为保障AI质量的重要环节,正受到越来越多专家学者和开发者的重视。本文将深入反思AI测试与评估的内涵、面临的挑战以及未来可能的发展路径,为读者呈现全面且前瞻的视角。 人工智能系统与传统软件有着本质的区别。传统软件测试通常关注功能正确性和性能表现,而AI系统则更多依赖数据驱动和模型自我学习,导致测试过程复杂且充满不确定性。
AI模型中不可预知的行为、黑箱性质以及数据分布的动态变化,使得测试方法和指标体系亟需创新。不同于传统测试,AI评估不仅关注准确率、召回率等性能指标,还需兼顾公平性、透明度、鲁棒性和安全性。例如,在医疗影像识别中,模型的错误判定可能带来严重后果,因此除了准确度外,对模型解释能力和异常检测能力的要求更高。 当前,AI测试面临的主要挑战之一是测试环境和测试用例的设计。由于AI模型依赖于庞大且多样化的数据,如何构建代表性强、覆盖面广的数据集成为难点。数据质量的好坏直接影响测试结果的可信度。
同时,测试用例应涵盖各种边界情况和异常场景,确保AI系统在复杂多变环境中依然稳定运行。此外,算法的不断更新迭代也要求测试机制具有高度的适应性和自动化,传统手工测试难以满足这一需求。 此外,AI系统的解释性和透明性问题也是评估过程中不可忽视的内容。黑箱模型虽然在任务性能上表现优异,但缺乏可解释性的问题限制了其在高风险领域的应用。因此,测试不仅要评估模型的输出结果,更需对模型的决策过程展开深入分析。可解释性测试方法通过对模型内部工作机制的可视化、特征重要性分析等手段,使开发者和用户能够理解模型行为,提升信任度并便于后续优化。
公平性和伦理性同样是现代AI测试与评估的重要议题。AI模型在训练数据中可能继承或放大社会偏见,导致对某些群体的不公平对待。如人脸识别系统识别率在不同人种间存在差异,招聘算法对特定性别的偏向等,这些问题都需要在测试阶段得到有效识别和修正。建立科学的公平性评估指标,设计多样化测试场景,有助于发现潜在的偏见并促使算法更加公正可信。 安全性测试则强调防护AI系统免受恶意攻击,如对抗样本攻击、模型窃取和数据篡改。这类攻击可能导致系统产生错误决策,影响实际应用效果。
针对这些威胁,测试团队需要模拟各种攻击场景,评估系统在应对恶意行为时的表现和恢复能力。只有经过严密安全测试的AI模型,才能在复杂多变的网络环境中保障数据和用户安全。 随着AI技术不断迈向自动化和智能化,测试技术也在不断演进。自动化测试工具和平台正在成为主流,通过结合机器学习方法生成测试用例和进行模型评估,大幅度提升测试效率。同时,持续集成与持续交付(CI/CD)理念的引入,确保AI模型能够快速迭代且保持高质量标准。此外,云计算和边缘计算环境下的测试体系建设,促使AI测试向着分布式、实时化方向发展,以应对日益增长的业务需求。
未来,AI测试与评估将更加注重多模态、多任务和跨领域的综合能力。AI系统不仅要掌握单一任务,更需具备适应不同场景的能力,这对测试方法提出了更高要求。跨领域的数据融合与模拟测试将成为重要趋势。同时,标准化和规范化流程的建设也日益关键。全球范围内关于AI伦理、安全与性能的标准制定,推动测试评估向更加透明、公正和科学的方向迈进。 总之,人工智能测试与评估作为支撑AI技术健康发展的基石,其重要性不言而喻。
充分认识AI独特的测试挑战,结合先进的测试技术和策略,不断完善评估体系,是确保AI在实际应用中发挥最大价值的关键。展望未来,随着技术和方法的持续创新,我们有望构建更加智能、安全、可信赖的AI生态,为社会带来深远的福祉与变革。