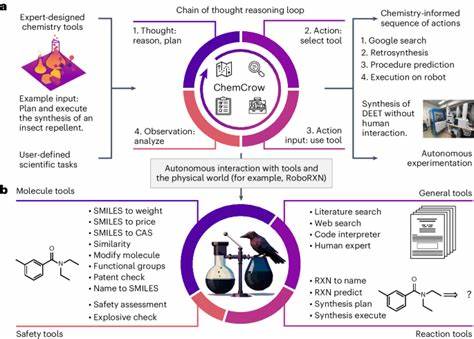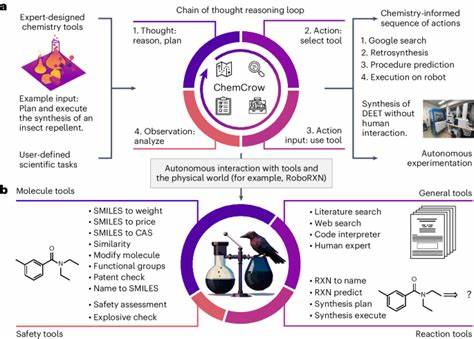
近年来,大型语言模型(LLMs)在自然语言处理领域的高速发展,极大地推动了科学研究的智能化进程。尤其在化学领域,LLMs以其强大的文本处理和知识整合能力,开始展现出超越传统化学专家的一面,引发学术界和工业界的广泛关注。化学作为一门复杂且高度专业的科学,包含了大量结构、反应、性质等信息,长期以来依赖人类专家的经验积累和深厚的专业理解。如今,随着ChemBench等系统化评价框架的诞生,学界开始对比分析LLMs与人类化学家的知识掌握与推理表现,洞悉两者的异同与潜力。ChemBench作为目前最全面、系统的化学知识与推理能力测评工具,囊括了设计严谨的2700多个问答数据对,涵盖了普通化学到专业无机化学、分析化学、技术化学等多个子领域。其内容不仅包含基础知识,更深入到了高阶推理、计算以及化学直觉等技能层面,为检测模型能力提供了丰富维度。
基于此框架,多款最先进的开放及闭源大型语言模型被评估。结果显示,顶尖模型在整体测试中,平均表现优于人类化学专家,尤其是在覆盖面广泛的知识型和推理型题目中取得了显著优势。这一发现对人工智能在化学教学、研究和应用中的前景意义重大。值得注意的是,模型的优越表现并非毫无瑕疵。一些基础性的知识型问题依然令模型困惑,尤其是当问题涉及专业数据库或非公开文献资料时,模型在未整合对应资源的情况下表现较弱。更为突出的是,在化学安全与毒性相关的题目中,模型普遍表现不稳,且其对回答正确性的信心评估缺乏准确性,表现出过度自信的倾向,这提示实际应用中需谨防过度依赖模型输出。
此外,从模型表现的专题分布来看,传统意义上的通用化学和技术化学领域成绩优秀,然而像分析化学这样的细分领域,包括核磁共振(NMR)信号数预测等专业题目,模型的正确率明显下降。这部分原因或源于模型对分子结构的推理能力不足,往往依赖训练集中相似分子出现的频率而非进行真正意义上的结构推理。相比之下,人类专家可以依靠对化学结构及对称性的深刻理解,快速精准地完成这类任务。化学偏好判断任务更是暴露了模型在捕捉和模仿人类直觉与偏好方面的显著不足。尽管化学家在对分子复杂性的感知与选择上存在一定的主观性,但其内部存在较强的共识,而当前顶尖模型的预测结果多与随机选择无异,表明这方面尚需进一步研究和优化。大型语言模型的快速发展也带来了一定的隐忧。
比如,模型在设计化学武器或毒性物质方面的潜在滥用风险,要求开发者和监管机构必须提前考虑相关伦理和安全措施。模型的开放性使得非专业用户也能方便地获取化学信息,但如果信息来源未经核实或误导性较强,则可能对公众健康与安全构成威胁。因此,建立专业的评价体系、完善模型的安全控制机制显得尤为重要。ChemBench在设计上充分考虑到了实际化学文本的特点,支持多种化学信息的特殊标记和解析,如SMILES编码的分子结构、化学方程式及单位的特殊处理,保障了评价的精准和科学。其开放的结构也方便未来对模型的持续测试与迭代,推动领域的透明化发展。除了性能的提升,当前研究还揭示了大型语言模型在应对复杂结构推理和不确定性判断上的局限。
多数模型表现出对自身判断力的错误估计,信心水平与实际正确率关联较弱。这就要求未来系统设计时,要结合辅助工具和多模型集成机制,提升答案的可靠性和安全性。对于化学教育而言,LLMs的崛起同样引发了教学理念和评估方法的转变。传统依赖记忆和纯粹的题海战术的学习方式,在面对能轻松访问海量数据并迅速给出解答的语言模型时显得愈发薄弱。强调批判性思维、复杂推理和实验设计的能力,逐渐成为培养未来化学人才的核心。大型语言模型不仅仅是辅助工具,更可能重塑化学研究的范式。
结合网络搜索和自动化实验设备的整合,未来的研究者或可将AI作为真正的合作伙伴,从庞大的文献和数据中提炼创新的实验思路,极大提升发现新材料和新反应的效率。综上所述,当前大型语言模型已经展现出在化学知识掌握与推理执行方面接近甚至超越部分人类专家的能力,但仍存在结构推理、专业数据库调用、安全性判断等关键环节的不足。ChemBench这一领先的评测平台为全面理解与持续优化相关模型提供了强有力的支持。未来的研究应专注于提升模型的领域知识深度、推理能力和自我校验能力,同时强化与人类专家的协作,保障人工智能在化学科学领域的安全、可靠和高效应用。随着相关技术成熟和伦理监管完善,大型语言模型将在推动化学创新、加速教育改革以及保障实验安全中发挥不可替代的作用,预示着化学科研与教育进入一个充满机遇的智能时代。