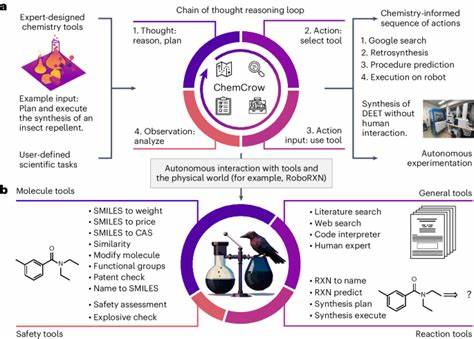
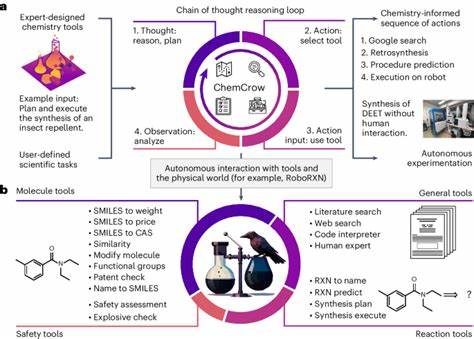
近年来,随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)和大型推理模型(LRM)的广泛应用,关于这些模型在复杂推理任务中的表现和潜在局限性的讨论日益增长。苹果公司近期发表的一篇关于LRM的研究论文引发了业界强烈关注,该论文揭示了LRM在精确计算和推理过程中的显著限制。紧随其后,一篇由Claude Opus参与署名的回应论文试图反驳苹果的观点,但受到多个AI专家的质疑,认为其论证存在严重不足,未能有效回应原论文的核心发现。这篇文章将详细分析Claude回应论文存在的问题,阐述为什么其无法构成对苹果LRM论文的有力反驳,并探讨这场学术争论对未来人工智能研究的意义。苹果LRM论文的核心观点在于指出当前大型语言模型和推理模型在处理复杂计算任务时,尤其是需要精确算法执行的场景,表现出明显的能力瓶颈。该论文以多个经典难题为例,说明模型在生成推理链的长度、复杂性以及解决问题的准确性方面存在系统性下降。
核心论断指出,尽管模型理论上具备生成更长推理过程的能力,但在遇到更高难度问题时,反而“放弃”了拓展推理步骤,选择了较短且不充分的回答路径,导致准确性骤降。该发现被多位业界权威如Subbaro Kambhampati和Yann LeCun认可,进一步强调了这一研究的影响力和可信度。反观Claude回应论文,据观察者分析,其最显著的问题是未能准确理解和回应苹果论文的核心论点。回应文中混淆了推理过程的复杂性与执行步骤的长度,将亚当斯谜题中的塔汉诺问题的步骤数量视作推理难度的直接衡量,错误地假设解决此类问题的token需求应呈现二次增长。然而,实际情况如AI专家Andreas Kirsch所指出,托汉诺问题的token增长是线性的,且模型能够在可控token数量内生成完整解答。由此导致回应论文在数学理论基础和推断逻辑上的重大误判。
更为关键的是,回应论文忽视了苹果团队关于“模型主动限制推理长度”的发现。在原论文中,尽管模型仍有足够的token预算和计算资源,但面对高难度问题时,竟自主选择缩减推理轨迹,表现出某种程度的“任务退缩”,这反映了推理机制中存在深层次限制。回应论文不仅未能解释这种现象,反而借助不同格式的输出结果(如Lua函数代码)证明模型能够高效解决大规模问题,这种选择性展示引发了矛盾,反而佐证了原论文的推理瓶颈论断。此外,回应论文的研究视角过于狭隘,局限于对模型是否能在token限制内完成任务的讨论,却未触及更为重要的推理质量和过程控制方面的问题。苹果论文重点并非单纯追踪模型完成任务的准确率,而是深入剖析模型推理路径的复杂度与系统性退化,强调传统推理基准过于关注最终答案,忽略了推理过程的连续性和一致性。Claude回应稿完全回避了这一角度,未能提供合理解释说明为何模型在复杂任务上会自我限制推理步骤,未回应苹果论文提出的“reasoning effort reduction”和“accuracy collapse”的现象。
此类忽视核心发现的处理方式,使得回应无法回应苹果论文所标示的推理架构本质限制。学界对大型语言模型推理能力的讨论从未停止。除了苹果团队的贡献,佐治亚理工学院和Subbaro Kambhampati等人的研究也陆续揭示了现有模型在逻辑推理、规划及多阶推断中的瓶颈。许多研究均指出,当前架构设计依赖于模式匹配和统计相关性,缺乏明确的符号推理机制和结构化思维,这导致模型在遇到复杂任务时表现出有限的推理链生成能力和不稳定的推理一致性。Gary Marcus等资深AI研究者也支持这种观点,呼吁探索结合符号推理与神经网络的混合模型,以突破纯机器学习模型的限制。综上所述,Claude回应论文因基本的数学错误、混淆推理复杂度与执行步骤、忽视模型主动限制推理链长度的核心发现以及过分聚焦于表面准确率而忽略深层推理特性的缺失,最终未能有效反驳苹果LRM论文所揭示的模型固有限制。
当前大型语言模型在面对复杂推理任务时,依然面临关键的架构和机制挑战,这要求学术界持续深入研究模型内部的认知模式和推理动力学。未来的人工智能研究应更加注重模型推理过程的透明性和连贯性,而非单纯追求结果准确性和扩展输出长度。只有如此,才能逐步实现真正具备类人推理能力的智能系统,推动人工智能迈向更高层次的智能化。