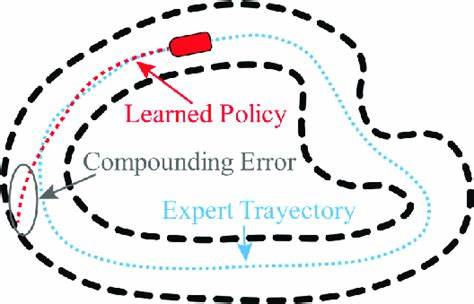
随着人工智能技术的不断进步,大语言模型(LLM)智能体正日益广泛应用于数据分析、自动问答、任务规划等多种复杂场景。然而,伴随着这些令人期待的能力背后,悄然存在着一个不容忽视且日益加剧的问题——误差的复合累积,即复合误差(compounding errors)现象。误差在每一步推理或决策中不断积累,最终导致系统输出结果的严重偏差,甚至宛如失控的机器人般失败。理解这种现象的本质,以及如何应对它,成为现代人工智能研究和工程实践中亟待解决的核心议题。计算机科学作为支撑数字时代的基础学科,早在上世纪便对误差传播机制有深入研究。Wilkinson在1963年发表的论文《代数过程中的舍入误差》揭示了数值计算中错误如何随着计算步骤的增加按规律叠加。
而Goldberg在1991年对浮点数算术的研究更证明了简单运算中的精度损失是不可避免的。浮点数标准IEEE 754的制定,便是解决这类累计误差导致系统失效风险的关键成果。相比之下,机器人学工程师面对复杂的物理系统早已将误差累积问题当成硬性挑战。传感器数据噪声随观测次数的增加以二次方速率增长,这使得基于这些数据的导航与定位极易失准。SLAM技术的发展正是为了通过统计建模和闭环反馈,减缓误差扩散并保持机器人的环境认知稳定。规划算法领域提出了配置空间障碍物的概念,强调在不考虑误差补偿的情况下,路径规划仅能在有限步骤内保持有效,过多的推演将令决策失效。
大语言模型智能体则处于计算机科学数字误差和机器人学物理误差问题之间,但其面临的挑战更加玄妙且难以量化。推理步骤中,模型输入的微小不确定性会在语义空间内扩散,既不像数字误差那样易于测定,也不像机器人传感器误差可以直接校准。更糟糕的是,其中充斥着难以察觉的谬误,例如虚假事实的“幻觉”与误解,直到后续推理或决策失败后才能暴露其影响。理论数学却早已揭示了这类系统不稳定的真相。Higham关于数值算法准确性与稳定性的研究说明,误差传播遵循条件数规律,而LLM推理的“条件数”对应于语义推理步骤对输入波动的敏感度。信息论大师Shannon证实,在任何噪声信道中,信息传递必然衰减,缺乏错误修正编码的语义推理链同样会出现语义信息的指数衰减。
控制论中,开环系统无法在多次迭代中保持稳定,类似目前多数LLM智能体架构,缺乏闭环反馈与自我纠错机制,因此注定误差会成倍放大。尽管如此,学界亦有乐观声音认为大型语言模型或许天生具备某种自我纠正或语义鲁棒机制。研究者Brown等人的GPT-3论文中提出“涌现能力”,暗示规模足够庞大的模型可能具备内在的误差检测和修正能力。另一方面,Hendrycks的深入测评彰显了大模型在面对输入扰动时表现出一定程度的韧性,显示语义系统或许比数值系统更具容错空间。Wei等人的连锁思维提示技术(Chain-of-Thought Prompting)证明充分上下文可以帮助模型在一定程度上修正早期错误,预示语义推理可能拥有自我修复的潜能。此外,规模扩展法则(Scaling Laws)暗示随着模型体积的增大,其错误率或许能有效降低。
然而,实际观察却给了这一乐观预期沉重打击。Kadavath等人在研究中发现模型的自我纠正能力缺乏稳定性,常常在复杂任务中失灵。Ribeiro的行为测试证实,表面上的鲁棒性掩盖了对特定语义扰动的高度敏感,极易乘虚而入并放大误差。Liu等人揭示长文本上下文中的信息丢失导致推理效果急剧恶化,破坏所谓语义自愈的假设。Ganguli等人进一步指出,即便规模极大,幻觉和推理失败依旧普遍存在,无法通过简单扩大参数量根治。详尽的实证研究更明确描绘了误差复合的严峻现实。
Wei等人的实验数据显示,随着推理步骤从两步增长到八步,准确率从78%暴跌至31%,印证了误差按指数衰减模型传播。Press的研究揭示模型性能下降恰如数学中预测的幂律衰减规律。Huang的调研揭示,事实错误常以高达73%的概率导致连锁反应破坏后续推理,且错误检测能力随步骤增加显著下降,使系统昼夜难掩失控的危机感。Dziri将此问题量化得更加透彻:即便单步准确率达到90%,连续十步后整体表现也仅剩35%,由此可见复合错误带来的灾难性叠加效应。Gao的研究发现,误差在初期以线性方式增长,然而进入中后期阶段后迅速转为指数甚至爆发式攀升,导致超过80%的任务失败率。来自实践环节的案例同样惨烈。
Shinn报告了WebShop任务中多步购物失败率高达68%,而HotPotQA中多跳问答准确率从82%骤降至34%。代码生成环境往往输出语法正确却功能残缺的软件,正是初期设计决策错误未被及早捕捉所致。Yao的《思想树》论文总结,多步推理可靠性下降速度远超早期期望,直接警示行业需正视这一问题根本。探讨为何复合错误问题在人工智能领域鲜被充分关注和解决,背后隐含着深层次的文化与产业因素。计算机科学及机器人学因涉及物理系统,面对失控后果无法回避,故强制推行严密的误差管理体系。相比之下,LLM系统生成的错误往往不迅速显现,且表现形式多为“边缘情况”或“提示技巧问题”,容易被忽视甚至误判。
同时,当前AI产业环境强烈强调快速迭代与创新,压制了对系统可靠性深入研究的投入,导致缺少推动基础性误差治理的动力。技术复杂性带来的神秘感,让研发者过分依赖模型规模和数据量,忽视了系统设计严谨性,反映了Perrow《正常事故》理论中对复杂系统隐患的警示。此外,跨学科知识壁垒阻碍了计算机科学与机器人学成熟经验向AI领域的有效迁移。如何有效借鉴三大领域经验,成为破解LLM误差累积难题的关键。首先,可引入数值计算中的条件数概念,设计语义条件数衡量机制,有助于识别哪些推理步骤对输入不确定性尤为敏感,从而优先进行强化和检测。其次,机器人领域成熟的闭环反馈体系值得借鉴,须为LLM工作流建立多层验证环节,确保输出正确性后才能继续下一步,避免误差无限放大。
再者,信息论中的纠错编码原理启示研究人员设计基于语义的冗余机制,为推理过程提供容错能力。具体方法包括建立置信度追踪系统,基于贝叶斯深度学习实时量化不确定性,同时利用多路径独立推理与投票机制实现冗余校验。语义校验和则可作为自动误判侦测工具,为人工干预提供准确预警。此外,系统设计需预留“优雅退化”机制,在发现可靠性低于阈值时及时切换到人工监管,避免灾难级风险蔓延。当前关于LLM智能体的讨论常在“万能智能”与“注定失败”的极端论调之间摇摆,实际上它们应被视作典型的工程系统,必然受到数学与物理定律约束。只有借鉴计算机科学与机器人学数十年累积的严谨实践理念,构建有理有据的误差管理框架,才能跨越现有性能瓶颈,迈向真正可用的生产级应用。
随着LLM技术被广泛引入金融交易、医疗诊断、基础设施管理等关键领域,复合误差带来的风险成本将以指数级上升。不能再像机器人那样因物理故障被不可忽视地摆在台面上,智能体的语义失控若长时间“潜伏”只会积轻成重。未来AI系统的可持续健康发展,必须汲取机器人学的教训,坚决将误差纠正作为设计首要原则。错误不再是“边缘”或“次要”,而必须成为工程管理的核心。时代的拐点已经到来,下一代智能体的胜负关键不再仅在规模与训练数据,而在于我们如何严肃解决误差复合的顽疾。AI行业应警醒,不要重复过去因忽视误差积累而付出的惨痛代价。
下一次你看到一个看似完美的多步骤智能体演示时,务必问一句:在千万次真实运转中,这套系统的错误率究竟是多少?因为在复合误差的世界里,一次惊艳从不代表能承受住第二次考验。唯有踏实推动误差管理和纠正技术,方能将LLM智能体的潜力稳妥释放,构建安全可信赖的未来智能生态。