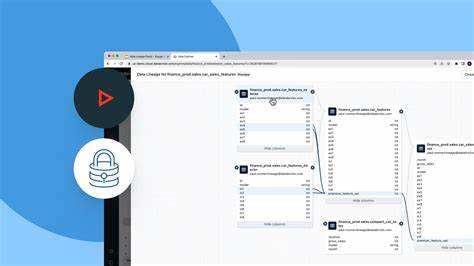
在大数据与云计算时代,数据量呈现爆炸式增长,如何高效管理分散在不同系统与平台中的海量数据,成为企业亟需解决的重要课题。Marmot正是在这种背景下诞生的一款开源数据目录系统,旨在帮助团队轻松发现、理解和治理数据资产,简化数据管理流程,提高数据利用率。其设计理念聚焦于简洁易用、性能优越及高度可扩展,使得Marmot成为现代数据架构中不可或缺的利器。 Marmot的核心优势在于其卓越的搜索能力和全面的数据血缘可视化功能。用户可以通过灵活的布尔查询、文本搜索以及元数据过滤,快速定位所需数据资产。无论是查找特定表、流数据管道还是关联的API,Marmot均能迅速响应,极大提升数据探索效率。
与此同时,其交互式血缘图展示了数据在不同系统间的流动和依赖关系,帮助用户理解数据来源与影响范围,推进精准的数据治理和风险控制。 简洁是Marmot设计的重中之重。系统采用单一二进制部署方式,降低了安装和维护复杂度,避免了繁琐的分布式组件配置,极大节约企业的时间和人力成本。整体界面直观友好,即使非技术背景的业务人员也能够快速上手,实现团队的跨部门协作和信息共享。此外,丰富的API与基础设施即代码(IaC)集成支持Terraform与Pulumi,确保Marmot能够灵活地嵌入现代DevOps与数据管道环境,满足不同企业的技术栈需求。 Marmot支持多种数据源的资产采集,拥有不断丰富的插件生态。
当前涵盖Kafka、AsyncAPI、PostgreSQL、AWS SQS、SNS等流行数据系统,用户通过CLI或API方式灵活导入数据资产。对未覆盖的场景,Marmot的开放API接口及IaC扩展允许无缝接入自定义数据类型,使得数据目录的构建更具弹性和适应力,无论是传统数据库、消息队列还是云端服务均能兼容管理。 数据治理方面,Marmot提供了完整的文档支持和分类标签功能。用户可以为数据资产编写Markdown格式的详细说明,结合分类标签实现分门别类管理,促进数据资产标准化与规范化。清晰的文档不仅便于新成员理解数据逻辑,也方便审计合规及知识传承,形成持续优化的数据文化。 在实际应用中,Marmot能够帮助数据团队快速定位问题根源,提升数据质量监控效率。
例如,某金融机构通过Marmot进行数据血缘分析,清晰追踪复杂的数据转换链路,有效减少了因数据不一致引发的业务风险;又如互联网企业借助其强大的搜索功能,多维度筛选日志与指标数据,实现对线上异常的快速响应,保障系统稳定运行。 技术实现方面,Marmot主体使用Go语言开发,确保高性能和良好的跨平台兼容性;前端采用Svelte框架,为用户提供灵敏且现代化的交互体验。项目采用开源模式,社区贡献持续活跃,版本更新频繁,快速迭代功能,满足用户不断变化的需求。 此外,Marmot提供了完善的本地开发环境支持,方便开发者在Docker环境下部署PostgreSQL数据库及前后端服务,实现快速调试和功能扩展。详尽的API文档与示例代码助力定制集成,实现与现有数据生态的无缝对接。 总体来看,Marmot通过简洁高效的架构设计和功能创新,帮助企业构建透明可控的数据资产体系,提升数据价值的挖掘与利用程度。
其强大的搜索能力与数据血缘可视化工具不仅改善了数据探索体验,也为数据治理和合规提供了坚实基础。未来,随着插件系统和社区生态的不断丰富,Marmot有望在国内外数据管理领域发挥更大影响力,成为数据团队不可或缺的得力助手。 总结而言,Marmot以追求简单、高效和灵活为核心,成功打造了一款适应现代数据生态需求的开源数据目录解决方案。无论是数据科学家、分析师还是运维人员,均能借助Marmot实现数据的快速发现、精准理解与有效治理,促进数据驱动决策,助力企业迈向智能化数字未来。