随着人工智能技术的迅猛发展,业界和学术界不断探索构建更为智能、适应性更强的系统,以实现真正具备通用智能的人工智能(AGI)。在这条道路上,Facebook首席人工智能科学家Yann LeCun提出的联合嵌入预测架构(Joint Embedding Predictive Architecture,简称JEPA)引起了广泛关注。JEPA不仅为世界建模提供了一种新颖的范式,还为解决当前主流AI模型在常识推理、长期规划及数据效率等方面的瓶颈提供了创新思路。本文将全面剖析Yann LeCun的JEPA理论体系、技术细节及其最新应用进展,试图阐释其对未来人工智能发展的深远影响。当前人工智能技术,尤其是大型语言模型(LLMs)和生成式AI,凭借在自然语言处理、内容生成等方面的卓越表现赢得了公众的高度认可。然而,这些模型在面对真实性验证、复杂推理和长期规划等核心能力时存在明显不足。
以自动驾驶领域为例,尽管投入了巨额资金和海量数据,现有自动驾驶系统仍未能达到人类驾驶者的灵活性与安全性。这一案例反映了大规模预训练模型虽强于特定任务,但尚无法实现快速、灵活的自主学习和复杂场景中的合理决策。Yann LeCun指出,这些不足的根源在于现有模型缺乏对“世界模型”的深刻理解,缺少高效的抽象表示和对未来可能性的多样预测能力。JEPA应运而生,旨在构建一个能够在隐空间进行多元化预测的能量模型,以解决这一难题。JEPA的核心理念是通过学习图像、视频或其他模态数据的嵌入表示,进而预测未来状态的嵌入表达,从而实现对世界状态的抽象建模。与传统的基于生成的模型不同,JEPA采用能量函数来判断当前预测是否合理,重点在于区分什么是可能发生的,而非确定性地预测具体未来内容。
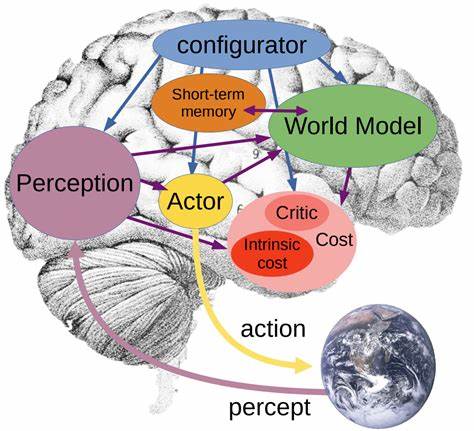
这一方式有效避免了生成模型常见的模糊或不确定性问题,提升了模型的预测准确性和鲁棒性。JEPA还引入了潜变量来表达未来状态的不确定性,这使得模型能够同时考虑多个可能的未来场景,为规划和决策提供丰富的备选。Yann LeCun的JEPA构想不仅仅停留在单一模态的视觉感知,而是强调多模态融合,结合视觉、语言、动作等多源信息构建完整的世界模型。基于JEPA的系统架构包含多个关键组件——感知模块负责即时环境信息提取;世界模型则完成对未来状态的预测和模拟;成本模块评估不同状态下的“成本”或“能量”,可视为奖励与惩罚的综合评估;配置器和行动者则分别管理任务目标和执行策略。通过这种模块化设计,JEPA试图赋予AI系统类似人类的意识形态和规划能力,实现自适应、自驱动的智能行为演化。JEPA背后的技术支撑是能量基模型(Energy-Based Models,EBM)和自监督学习(Self-Supervised Learning,SSL)。
EBM通过设计能量函数来衡量数据样本与输入的兼容性,避免了概率密度建模的复杂性。然而,EBM往往面临“能量坍塌”问题,JEPA利用对比学习和正则化技术有效避免了坍塌,提升模型稳定性。自监督学习则充分发挥了无标签数据的优势,极大提高了模型对多样环境的泛化能力,将人工智能的学习过程趋近于人类婴儿的认知发展。此外,JEPA强调层级建模(Hierarchical JEPA)。这一架构分为多个抽象层,低层次处理短期、局部信息,允许模型在高维空间中捕捉细节特征;高层次则进行长期、全局预测,实现对未来状态的宏观规划。层级设置不仅提高了模型对复杂时空动态的理解力,也为长时间尺度的推理与决策提供了坚实基础。
JEPA的研究团队和社区已基于理论构想开发出多个具体实现版本。I-JEPA针对图像进行自监督训练,通过Patch切分及局部上下文编码,捕获高效视觉特征,实现对于局部信息的预测;V-JEPA进一步拓展至视频领域,将视频帧视为三维空间切片,引入时序上下文,使模型可学习连续时间段内动作及内容关系;MC-JEPA则结合光流等运动信息,进一步提升动作特征的捕捉能力,展现出强大的多任务学习优势。在2025年最新发布的V-JEPA 2中,研究人员大幅扩大模型规模和训练数据集,采用混合视频数据集(VideoMix22M)和更长序列的训练方式,极大提升模型对长时间跨度视频的理解和预测能力。更重要的是,V-JEPA 2首次引入了多模态任务的后期训练技术,包括与大型语言模型(LLMs)的结合,实现了视频问答以及动作预测等复杂任务,展示了JEPA架构在实际应用中的巨大潜力。在机器人领域,V-JEPA 2通过动作条件化训练,利用真实机器人操作数据指导模型预测动作序列,不仅加速了机器人的规划与执行,还展示了出色的任务适应能力,为智能机器人系统注入了更强的环境感知和自我调整能力。伴随JEPA架构的不断成熟和应用扩展,未来人工智能系统或将实现真正意义上的“思考”和“规划”。
通过引入系统1与系统2的不同思维模式,AI可以实现快速反应与深度推理的结合。系统1对应快速、本能的即时决策,系统2则通过JEPA的世界模型进行前瞻性规划和多步骤推理,使AI能像人类一样应对复杂变化的环境,避免当前深度学习模型单步生成带来的错误累积。JEPA同时回应了人类智能中的关键问题——数据效率与常识获取。人脑从婴儿期开始便通过有限的感官数据和经验,迅速构建世界模型,具备强大的泛化推理能力。JEPA通过自监督和层级预测机制,试图模拟这一过程,减少对海量标注数据的依赖,提高AI的快速学习能力。未来,随着多模态数据的丰富和计算能力的提升,JEPA有望结合语言、视觉、听觉以及行动反馈,构建具备“常识”与“自我意识”的智能体,跨越现有AI在场景理解、规划决策、推理能力上的瓶颈。
总之,Yann LeCun提出的联合嵌入预测架构(JEPA)代表了人工智能领域一次颠覆性的创新尝试。它融合能量基模型和自监督学习的优势,将视觉与其他模态紧密结合,推动从表象到抽象的多层次世界建模。最新的V-JEPA 2已在视频理解、机器人规划等多领域展现出强大潜力。未来,JEPA或将引领人工智能迈向具备高级认知、推理与规划能力的新时代,成为实现人类级智能的重要基石。随着相关研究不断深入和应用场景扩展,我们有理由期待JEPA在赋予机器真正“思考”能力上发挥关键作用,推动智能时代的再一次飞跃。